While training a UiPath Communications Mining model, the Search feature was used to pin
a certain label on a few communications. After retraining, the new model version starts to
predict the tagged label but infrequently and with low confidence.
According to best practices, what would be the correct next step to improve the model's
predictions for the label, in the "Explore" phase of training?
A. Use the "Rebalance" training mode to pin the label to more communications.
B. Use the 'Teach" training mode to pin the label to more communications.
C. Use the "Low confidence" training mode to pin the label to more communications.
D. Use the "Search" feature to pin the label to more communications.
Explanation: According to the UiPath documentation, the ‘Teach’ training mode is used to improve the model’s predictions for a specific label by pinning it to more communications that match the label’s criteria. This helps the model learn from more examples and increase its confidence and accuracy. The ‘Teach’ mode also allows you to unpin the label from communications that do not match it, which helps the model avoid false positives. The other training modes are not as effective for this purpose, as they either focus on different aspects of the model performance or do not provide enough feedback to the model.
What is Document Understanding?
A. A solution for combining different approaches to extract information from workflows.
B. A solution that offers the ability to digitize, extract, validate, and train data from documents.
C. A solution for the processing of Excel files for extracting data tables.
D. A solution for combining different approaches to extract entities from Word documents such as contracts and agreements.
Explanation: Document Understanding is a tool that helps you create and manage documents for your automation scenarios in the UiPath ecosystem. It allows you to process and extract data from multiple document types in an open, extensible, and versatile environment. The framework consists of components such as Taxonomy, Digitization, Data Extraction, Data Extraction Validation, Data Extraction Training, and Data Consumption, and enables you to customize and train your own algorithms12.
How many types of synchronization mechanisms exist in the Document Understanding Process to prevent multiple robots to write in a file at the same time?2
A. 2
B. 3
C. 4
D. 5
Explanation: The Document Understanding Process uses two types of synchronization
mechanisms to prevent multiple robots from writing in a file at the same time: file locks and
queues. File locks are used to ensure that only one robot can access a file at a time, while
queues are used to store the information extracted from the documents and to avoid data
loss or duplication. The process uses the following activities to implement these
mechanisms:
File Lock Scope: This activity creates a lock on a file or folder and executes a set
of activities within it. The lock is released when the scope ends or when an
exception occurs. This activity ensures that only one robot can read or write a file
or folder at a time, and prevents other robots from accessing it until the lock is
released.
Add Queue Item: This activity adds an item to a queue in Orchestrator, along with
some relevant information, such as a reference, a priority, or a deadline. The item
can be a JSON object, a string, or any serializable .NET type. This activity ensures
that the information extracted from the documents is stored in a queue and can be
retrieved by another robot or process later.
Get Queue Items: This activity retrieves a collection of items from a queue in
Orchestrator, based on some filters, such as status, reference, or creation time.
The items can be processed by the robot or passed to another activity, such as
Update Queue Item or Delete Queue Item. This activity ensures that the
information stored in the queue can be accessed and manipulated by the robot or
process.
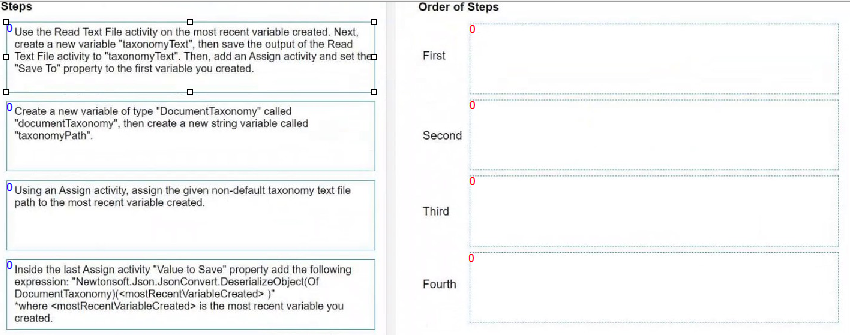
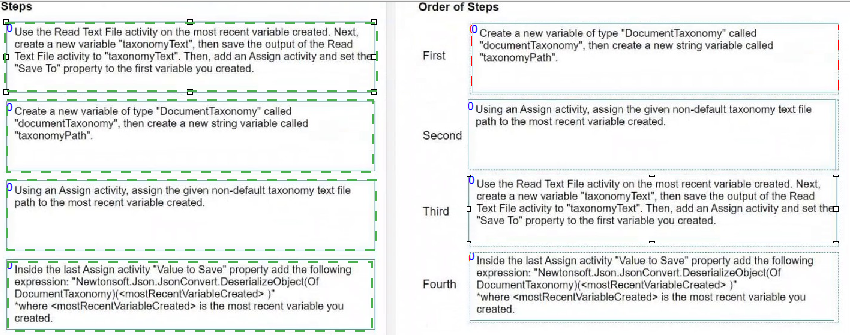
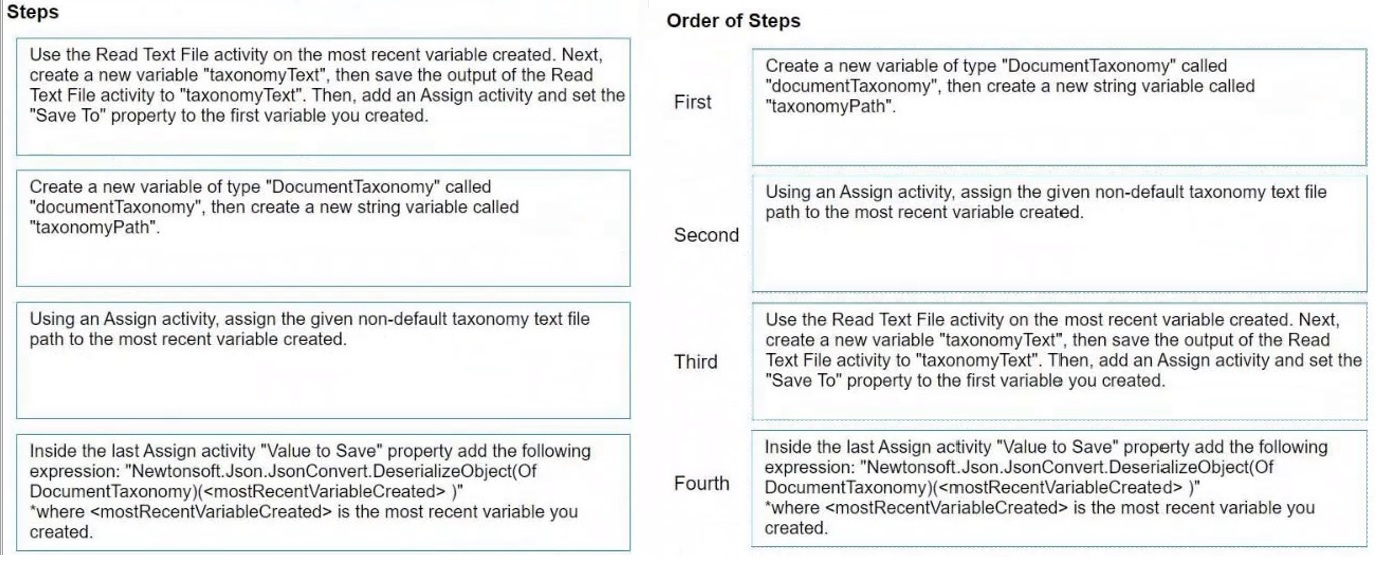
How do you load a taxonomy from a given non-default location text file into a variable?
Instructions: Drag the steps found on the "Left" and drop them on the "Right" in the correct
order.
Explanation:
C:\Users\Waqas Shahid\Desktop\Mudassir\Untitled.jpg
to load a taxonomy from a given non-default location text file into a variable, the order of
steps should be as follows:
Create a new variable of type 'DocumentTaxonomy' called 'documentTaxonomy',
then create a new string variable called 'taxonomyPath'.
Using an Assign activity, assign the given non-default taxonomy text file path to
the most recent variable created.
Use the Read Text File activity on the 'taxonomyPath' variable created. Next,
create a new variable 'taxonomyText', then save the output of the Read Text File
activity to 'taxonomyText'.
Inside the last Assign activity 'Value to Save' property add the following
expression: "Newtonsoft.Json.JsonConvert.DeserializeObject(Of
DocumentTaxonomy)(taxonomyText)" where 'taxonomyText' is the text read from
the file and 'documentTaxonomy' (the most recent variable created) is the variable
you created.
Following these steps in this order will load the taxonomy from a text file into the
'documentTaxonomy' variable in UiPath.
What do entities represent in UiPath Communications Mining?
A. Structured data points.
B. Concepts, themes, and intents.
C. Thread properties.
D. Metadata properties.
Explanation: Entities are additional elements of structured data which can be extracted from within the verbatims. Entities include data such as monetary quantities, dates, currency codes, organisations, people, email addresses, URLs, as well as many other industry specific categories. Entities represent concepts, themes, and intents that are relevant to the business use case and can be used for filtering, searching, and analyzing the verbatims.
What can the Custom Named Entity Recognition out-of-the-box model be used for?
A. Understand sentiment in product reviews, customer surveys, social media posts, and emails.
B. Classify text in resumes, emails, web pages, and other formats.
C. Relate customer questions to FAQ documents and automatically pull responses from these documents.
D. Extract and classify text in emails, letters, web pages, research papers, and call transcripts.
Explanation: The Custom Named Entity Recognition out-of-the-box model is a machine learning package that allows you to bring your own dataset tagged with entities you want to extract from unstructured text. The model can be trained and deployed using the UiPath AI Center, and can be integrated with the UiPath Document Understanding framework. The model can be used to extract and classify text in various domains and formats, such as emails, letters, web pages, research papers, and call transcripts. For example, you can use the model to extract information such as names, dates, addresses, amounts, products, or any other custom entity from your documents. The model supports multiple languages and can be customized according to your needs.
What is the default visibility of an ML skill?
A. An ML skill is by default public and can be made private.
B. An ML skill is by default private and can be made public.
C. An ML skill is by default public and can't be made private.
D. An ML skill is by default private and can't be made public.
Explanation: An ML skill is a consumer-ready, live deployment of an ML or OS package that can be used in RPA workflows. By default, an ML skill is private, which means it can only be accessed by the users who have the permission to view and manage the project that contains the skill. However, an ML skill can be made public by enabling the Public Skill option in the ML Skill Details page. This will generate a public URL and an API key for the skill, which can be used to access the skill from any external system or application12.
What is the difference between OCR (Optical Character Recognition) and IntelligentOCR?
A. OCR (Optical Character Recognition) is a method that reads text from images, recognizing each character and its position, while IntelligentOCR is an enhanced version of it that can also work with noisier input data.
B. IntelligentOCR is simply a rebranding of the OCR (Optical Character Recognition), both of them being methods that read text from images, recognizing each character and its position.
C. OCR (Optical Character Recognition) is a UiPath Studio activity package that contains IntelligentOCR as an activity used to read text from images, recognizing each character and its position. OCR is widely used in Document Understanding processes.
D. IntelligentOCR is a UiPath Studio activity package that contains all the activities needed to enable information extraction, while OCR (Optical Character Recognition) is a method that reads text from images, recognizing each character and its position.
Explanation: According to the UiPath documentation and web search results, OCR
(Optical Character Recognition) is a method that reads text from images, recognizing each
character and its position. OCR is used to digitize documents and make them searchable
and editable. OCR can be performed by different engines, such as Tesseract, Microsoft
OCR, Microsoft Azure OCR, OmniPaqe, and Abbyy. OCR is a basic step in the Document
Understanding Framework, which is a set of activities and services that enable the automation of document processing workflows.
IntelligentOCR is a UiPath Studio activity package that contains all the activities needed to
enable information extraction from documents. Information extraction is the process of
identifying and extracting relevant data from documents, such as fields, tables, entities, and
labels. IntelligentOCR uses different components, such as classifiers, extractors, validators,
and trainers, to perform information extraction. IntelligentOCR also supports different
formats, such as PDF, PNG, JPG, TIFF, and BMP. IntelligentOCR is an advanced step in
the Document Understanding Framework, which builds on the OCR output and provides
more functionality and flexibility.
What is the recommended number of documents per vendor to train the initial dataset?
A. 5
B. 10
C. 15
D. 20
Explanation: According to the UiPath documentation, the recommended number of documents per vendor to train the initial dataset is 10. This means that for each vendor that provides a specific type of document, such as invoices or receipts, you should have at least 10 samples of their documents in your training dataset. This helps to ensure that the dataset is balanced and representative of the real-world data, and that the machine learning model can learn from the variations and features of each vendor’s documents. Having too few documents per vendor can lead to poor model performance and accuracy, while having too many documents from a single vendor can cause overfitting and bias1.
Can you use Queues in the Document Understanding Process?
A. The Document Understanding Process can't use Queues because items waiting for Human Validation for more than 10 days will be marked as Abandoned.
B. The Document Understanding Process can use Queues but the Auto Retry Functionality should be disabled.
C. The Document Understanding Process can use Queues but the Auto Retry Functionality should be enabled.
D. The Document Understanding Process can't use Queues because items waiting for Human Validation for more than 24h will be marked as Abandoned.
Explanation: The Document Understanding Process is a fully functional UiPath Studio project template based on a document processing flowchart. It supports both attended and unattended robots with human-in-the-loop validation via Action Center. The process uses queues to store and process the input files, one file per queue item. However, the Auto Retry Functionality should be disabled on queues, because it can interfere with the human validation step and cause errors or duplicates. The process handles the retry mechanisms internally, using the Try/Catch and Error management features.
Which of the following is an indicator that sufficient training has been completed for a model in UiPath Communications Mining?
A. A model rating of 30-40.
B. A model rating of 40-50.
C. A model rating of 50-60.
D. A model rating of 70-90 or better.
Explanation: The model rating is a proprietary score that assesses the overall health and performance of a model in UiPath Communications Mining. It considers four main factors: balance, underperforming labels, coverage, and all labels. The model rating is a score from 0 to 100, which equates to a rating of ‘Poor’ (0-49), ‘Average’ (50-69), ‘Good’ (70-89) or ‘Excellent’ (90-100). A model rating of 70-90 or better indicates that the model has sufficient training and performs well in all of the most important areas. A model rating of 70- 90 or better also means that the model has a balanced and representative training data, a low number of labels with performance issues or warnings, a high coverage of the dataset by informative labels, and a high average precision of all labels.
Which of the below is the correct definition of "recall" in UiPath Communications Mining?
A. For a given concept what % of cases will the model incorrectly predict.
B. For a given concept, what % of cases will the model not detect.
C. For a given concept what % of cases will the model correctly predict.
D. For a given concept, what % of cases will the model detect.
Explanation: Recall is a metric that measures the proportion of all possible true positives that the model was able to identify for a given concept1. A true positive is a case where the model correctly predicts the presence of a concept in the data. Recall is calculated as the ratio of true positives to the sum of true positives and false negatives, where a false negative is a case where the model fails to predict the presence of a concept in the data. Recall can be interpreted as the sensitivity or completeness of the model for a given concept2. For example, if there are 100 verbatims that should have been labelled as ‘Request for information’, and the model detects 80 of them, then the recall for this concept is 80% (80 / (80 + 20)). A high recall means that the model is good at finding all the relevant cases for a concept, while a low recall means that the model misses many of them.
| Page 1 out of 7 Pages |