This file has been manually created on a universal forwarder
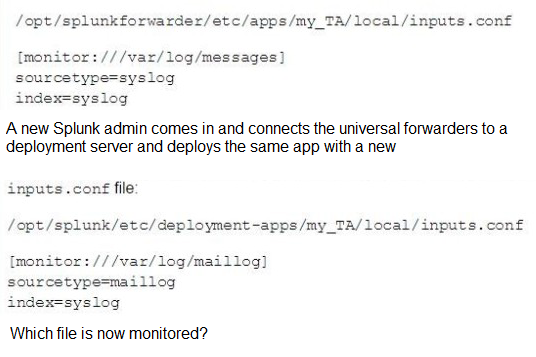
A. /var/log/messages
B. /var/log/maillog
C. /var/log/maillog and /var/log/messages
D. none of the above
An add-on has configured field aliases for source IP address and destination IP address fields. A specific user prefers not to have those fields present in their user context. Based on the defaultprops.confbelow, whichSPLUNK_HOME/etc/users/buttercup/myTA/local/props.confstanza can be added to the user’s local context to disable the field aliases?
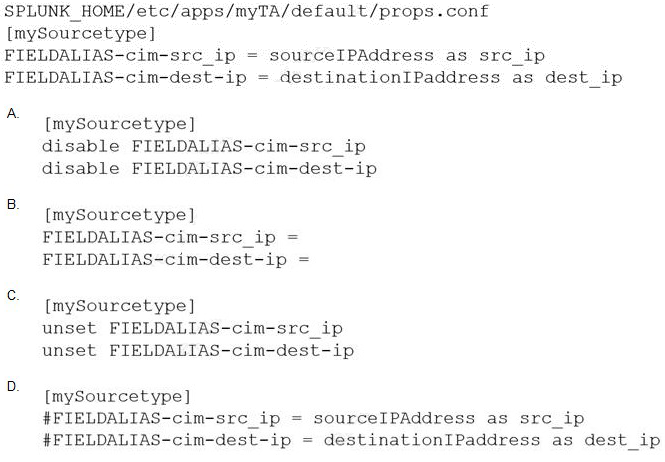
A. Option A
B. Option B
C. Option C
D. Option D
The following stanza is active in indexes.conf:
[cat_facts]
maxHotSpanSecs = 3600
frozenTimePeriodInSecs = 2630000
maxTota1DataSizeMB = 650000
All other related indexes.conf settings are default values.
If the event timestamp was 3739283 seconds ago, will it be searchable?
A. Yes, only if the bucket is still hot.
B. No, because the index will have exceeded its maximum size.
C. Yes, only if the index size is also below 650000 MB.
D. No, because the event time is greater than the retention time.
Explanation: The correct answer is D. No, because the event time is greater than the
retention time.
According to the Splunk documentation1, the frozenTimePeriodInSecs setting in
indexes.conf determines how long Splunk software retains indexed data before deleting it
or archiving it to a remote storage. The default value is 188697600 seconds, which is
equivalent to six years. The setting can be overridden on a per-index basis.
In this case, the cat_facts index has a frozenTimePeriodInSecs setting of 2630000
seconds, which is equivalent to about 30 days. This means that any event that is older than
30 days from the current time will be removed from the index and will not be searchable.
The event timestamp was 3739283 seconds ago, which is equivalent to about 43 days.
This means that the event is older than the retention time of the cat_facts index and will not
be searchable.
The other settings in the stanza, such as maxHotSpanSecs and maxTota1DataSizeMB, do
not affect the retention time of the events. They only affect the size and duration of the
buckets that store the events.
What is required when adding a native user to Splunk? (select all that apply)
A. Password
B. Username
C. Full Name
D. Default app
Explanation: According to the Splunk system admin course PDF, When adding native users, Username and Password ARE REQUIRED
Which option on the Add Data menu is most useful for testing data ingestion without creating inputs.conf?
A. Upload option
B. Forward option
C. Monitor option
D. Download option
In which phase of the index time process does the license metering occur?
A. input phase
B. Parsing phase
C. Indexing phase
D. Licensing phase
Explanation: "When ingesting event data, the measured data volume is based on the new raw data that is placed into the indexing pipeline. Because the data is measured at the indexing pipeline, data that is filtered and dropped prior to indexing does not count against the license volume qota."
In inputs. conf, which stanza would mean Splunk was only reading one local file?
A. [read://opt/log/crashlog/Jan27crash.txt]
B. [monitor::/ opt/log/crashlog/Jan27crash.txt]
C. [monitor:/// opt/log/]
D. [monitor:/// opt/log/ crashlog/Jan27crash.txt]
Explanation: [monitor::/opt/log/crashlog/Jan27crash.txt]. This stanza means that Splunk is monitoring a single local file named Jan27crash.txt in the /opt/log/crashlog/ directory1. The monitor input type is used to monitor files and directories for changes and index any new data that is added2.
A Universal Forwarder has the following active stanza in inputs . conf:
[monitor: //var/log]
disabled = O
host = 460352847
An event from this input has a timestamp of 10:55. What timezone will Splunk add to the
event as part of indexing?
A. Universal Coordinated Time.
B. The timezone of the search head.
C. The timezone of the indexer that indexed the event.
D. The timezone of the forwarder.
Explanation:
The correct answer is D. The timezone of the forwarder will be added to the event as part
of indexing.
According to the Splunk documentation1, Splunk software determines the time zone to assign to a timestamp using the following logic in order of precedence:
Use the time zone specified in raw event data (for example, PST, -0800), if
present.
Use the TZ attribute set in props.conf, if the event matches the host, source, or
source type that the stanza specifies.
If the forwarder and the receiving indexer are version 6.0 or higher, use the time
zone that the forwarder provides.
Use the time zone of the host that indexes the event.
In this case, the event does not have a time zone specified in the raw data, nor does it
have a TZ attribute set in props.conf. Therefore, the next rule applies, which is to use the
time zone that the forwarder provides. A universal forwarder is a lightweight agent that can
forward data to a Splunk deployment, and it knows its system time zone and sends that
information along with the events to the indexer2.The indexer then converts the event time
to UTC and stores it in the _time field1.
The other options are incorrect because:
A. Universal Coordinated Time (UTC) is not the time zone that Splunk adds to the
event as part of indexing, but rather the time zone that Splunk uses to store the
event time in the _time field. Splunk software converts the event time to UTC based
on the time zone that it determines from the rules above1.
B. The timezone of the search head is not relevant for indexing, as the search head
is a Splunk component that handles search requests and distributes them to
indexers, but it does not process incoming data3.The search head uses the user’s
timezone setting to determine the time range in UTC that should be searched and
to display the timestamp of the results in the user’s timezone2.
C. The timezone of the indexer that indexed the event is only used as a last resort,
if none of the other rules apply. In this case, the forwarder provides the time zone
information, so the indexer does not use its own time zone1.
Which parent directory contains the configuration files in Splunk?
A. SSFLUNK_HOME/etc
B. SSPLUNK_HOME/var
C. SSPLUNK_HOME/conf
D. SSPLUNK_HOME/default
Explanation:
https://docs.splunk.com/Documentation/Splunk/7.3.1/Admin/Configurationfiledirectories
Section titled, Configuration file directories, states "A detailed list of settings for each
configuration file is provided in the .spec file names for that configuration file. You can find the latest version of the .spec and .example files in the $SPLUNK_HOME/etc
system/README folder of your Splunk Enterprise installation..."
During search time, which directory of configuration files has the highest precedence?
A. $SFLUNK_KOME/etc/system/local
B. $SPLUNK_KCME/etc/system/default
C. $SPLUNK_HCME/etc/apps/app1/local
D. $SPLUNK HCME/etc/users/admin/local
Explanation: Adding further clarity and quoting same Splunk reference URL from @giubal"
"To keep configuration settings consistent across peer nodes, configuration files are
managed from the cluster master, which pushes the files to the slave-app directories on the
peer nodes. Files in the slave-app directories have the highest precedence in a cluster
peer's configuration. Here is the expanded precedence order for cluster peers:
A Universal Forwarder is collecting two separate sources of data (A,B). Source A is being routed through a Heavy Forwarder and then to an indexer. Source B is being routed directly to the indexer. Both sets of data require the masking of raw text strings before being written to disk. What does the administrator need to do to ensure that the masking takes place successfully?
A. Make sure that props . conf and transforms . conf are both present on the in-dexer and the search head.
B. For source A, make sure that props . conf is in place on the indexer; and for source B, make sure transforms . conf is present on the Heavy Forwarder.
C. Make sure that props . conf and transforms . conf are both present on the Universal Forwarder.
D. Place both props . conf and transforms . conf on the Heavy Forwarder for source A, and place both props . conf and transforms . conf on the indexer for source B.
Explanation: The correct answer is D. Place both props . conf and transforms . conf on the
Heavy Forwarder for source A, and place both props . conf and transforms . conf on the
indexer for source B.
According to the Splunk documentation1, to mask sensitive data from raw events, you
need to use the SEDCMD attribute in the props.conf file and the REGEX attribute in the
transforms.conf file. The SEDCMD attribute applies a sed expression to the raw data
before indexing, while the REGEX attribute defines a regular expression to match the data
to be masked.You need to place these files on the Splunk instance that parses the data,
which isusually the indexer or the heavy forwarder2. The universal forwarder does not
parse the data, so it does not need these files.
For source A, the data is routed through a heavy forwarder, which can parse the data
before sending it to the indexer. Therefore, you need to place both props.conf and
transforms.conf on the heavy forwarder for source A, so that the masking takes place
before indexing.
For source B, the data is routed directly to the indexer, which parses and indexes the data.
Therefore, you need to place both props.conf and transforms.conf on the indexer for source
B, so that the masking takes place before indexing.
When using a directory monitor input, specific source types can be selectively overridden using which configuration file?
A. sourcetypes . conf
B. trans forms . conf
C. outputs . conf
D. props . conf
Explanation: When using a directory monitor input, specific source types can be selectively overridden using the props.conf file. According to the Splunk documentation1, “You can specify a source type for data based on its input and source. Specify source type for an input. You can assign the source type for data coming from a specific input, such as /var/log/. If you use Splunk Cloud Platform, use Splunk Web to define source types. If you use Splunk Enterprise, define source types in Splunk Web or by editing the inputs.conf configuration file.” However, this method is not very granular and assigns the same source type to all data from an input. To override the source type on a per-event basis, you need to use the props.conf file and the transforms.conf file2. The props.conf file contains settings that determine how the Splunk platform processes incoming data, such as how to segment events, extract fields, and assign source types2. The transforms.conf file contains settings that modify or filter event dataduring indexing or search time2. You can use these files to create rules that match specific patterns in the event data and assign different source types accordingly2. For example, you can create a rule that assigns a source type of apache_error to any event that contains the word “error” in the first line2.
| Page 4 out of 16 Pages |
| Previous |