Topic 2: Misc. Questions
You are developing a single-player mobile game backend that has unpredictable traffic patterns as users interact with the game throughout the day and night. You want to optimize costs by ensuring that you have enough resources to handle requests, but minimize over-provisioning. You also want the system to handle traffic spikes efficiently. Which compute platform should you use?
A. Cloud Run
B. Compute Engine with managed instance groups
C. Compute Engine with unmanaged instance groups
D. Google Kubernetes Engine using cluster autoscaling
Your team develops services that run on Google Kubernetes Engine. Your team’s code is stored in Cloud Source Repositories. You need to quickly identify bugs in the code before it is deployed to production. You want to invest in automation to improve developer feedback and make the process as efficient as possible. What should you do?
A. Use Spinnaker to automate building container images from code based on Git tags.
B. Use Cloud Build to automate building container images from code based on Git tags.
C. Use Spinnaker to automate deploying container images to the production environment.
D. Use Cloud Build to automate building container images from code based on forked versions.
Your team is developing an application in Google Cloud that executes with user identities maintained by Cloud Identity. Each of your application’s users will have an associated Pub/Sub topic to which messages are published, and a Pub/Sub subscription where the same user will retrieve published messages. You need to ensure that only authorized users can publish and subscribe to their own specific Pub/Sub topic and subscription. What should you do?
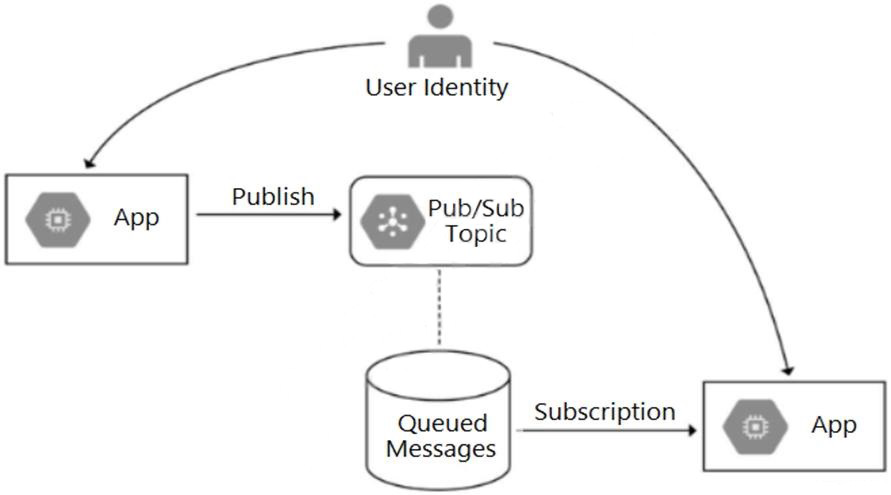
A. Bind the user identity to the pubsub.publisher and pubsub.subscriber roles at the resource level.
B. Grant the user identity the pubsub.publisher and pubsub.subscriber roles at the project level.
C. Grant the user identity a custom role that contains the pubsub.topics.create and pubsub.subscriptions.create permissions.
D. Configure the application to run as a service account that has the pubsub.publisher and pubsub.subscriber roles.
You have an application deployed in production. When a new version is deployed, some issues don't arise until the application receives traffic from users in production. You want to reduce both the impact and the number of users affected. Which deployment strategy should you use?
A. Blue/green deployment
B. Canary deployment
C. Rolling deployment
D. Recreate deployment
Your team is developing an ecommerce platform for your company. Users will log in to the website and add items to their shopping cart. Users will be automatically logged out after 30 minutes of inactivity. When users log back in, their shopping cart should be saved. How should you store users’ session and shopping cart information while following Google recommended best practices?
A. Store the session information in Pub/Sub, and store the shopping cart information in Cloud SQL.
B. Store the shopping cart information in a file on Cloud Storage where the filename is the SESSION ID.
C. Store the session and shopping cart information in a MySQL database running on multiple Compute Engine instances.
D. Store the session information in Memorystore for Redis or Memorystore for Memcached, and store the shopping cart information in Firestore.
Your security team is auditing all deployed applications running in Google Kubernetes Engine. After completing the audit, your team discovers that some of the applications send traffic within the cluster in clear text. You need to ensure that all application traffic is encrypted as quickly as possible while minimizing changes to your applications and maintaining support from Google. What should you do?
A. Use Network Policies to block traffic between applications.
B. Install Istio, enable proxy injection on your application namespace, and then enable mTLS.
C. Define Trusted Network ranges within the application, and configure the applications to allow traffic only from those networks.
D. Use an automated process to request SSL Certificates for your applications from Let’s Encrypt and add them to your applications.
You work for a financial services company that has a container-first approach. Your team develops microservices applications You have a Cloud Build pipeline that creates a container image, runs regression tests, and publishes the image to Artifact Registry You need to ensure that only containers that have passed the regression tests are deployed to Google Kubernetes Engine (GKE) clusters You have already enabled Binary Authorization on the GKE clusters What should you do next?
A. Deploy Voucher Server and Voucher Client Components. After a container image has passed the regression tests, run Voucher Client as a step in the Cloud Build pipeline.
B. Set the Pod Security Standard level to Restricted for the relevant namespaces Digitally sign the container images that have passed the regression tests as a step in the Cloud Build pipeline.
C. Create an attestor and a policy. Create an attestation for the container images that have passed the regression tests as a step in the Cloud Build pipeline.
D. Create an attestor and a policy Run a vulnerability scan to create an attestation for the container image as a step in the Cloud Build pipeline.
You recently deployed your application in Google Kubernetes Engine, and now need to release a new version of your application. You need the ability to instantly roll back to the previous version in case there are issues with the new version. Which deployment model should you use?
A. Perform a rolling deployment, and test your new application after the deployment is complete.
B. Perform A/B testing, and test your application periodically after the new tests are implemented.
C. Perform a blue/green deployment, and test your new application after the deployment is. complete.
D. Perform a canary deployment, and test your new application periodically after the new version is deployed.
Your analytics system executes queries against a BigQuery dataset. The SQL query is executed in batch and passes the contents of a SQL file to the BigQuery CLI. Then it redirects the BigQuery CLI output to another process. However, you are getting a permission error from the BigQuery CLI when the queries are executed. You want to resolve the issue. What should you do?
A. Grant the service account BigQuery Data Viewer and BigQuery Job User roles.
B. Grant the service account BigQuery Data Editor and BigQuery Data Viewer roles.
C. Create a view in BigQuery from the SQL query and SELECT* from the view in the CLI.
D. Create a new dataset in BigQuery, and copy the source table to the new dataset Query the new dataset and table from the CLI.
You have recently instrumented a new application with OpenTelemetry, and you want to check the latency of your application requests in Trace. You want to ensure that a specific request is always traced. What should you do?
A. Wait 10 minutes, then verify that Trace captures those types of requests automatically
B. Write a custom script that sends this type of request repeatedly from your dev project
C. Use the Trace API to apply custom attributes to the trace.
D. Add the X-Cloud-Trace-Context header to the request with the appropriate parameters.
Cloud Trace doesn't sample every request. To force a specific request to be traced, add an X-Cloud-Trace-Context header to the request.
Your company is planning to migrate their on-premises Hadoop environment to the cloud. Increasing storage cost and maintenance of data stored in HDFS is a major concern for your company. You also want to make minimal changes to existing data analytics jobs and existing architecture. How should you proceed with the migration?
A. Migrate your data stored in Hadoop to BigQuery. Change your jobs to source their information from BigQuery instead of the on-premises Hadoop environment.
B. Create Compute Engine instances with HDD instead of SSD to save costs. Then perform a full migration of your existing environment into the new one in Compute Engine instances.
C. Create a Cloud Dataproc cluster on Google Cloud Platform, and then migrate your Hadoop environment to the new Cloud Dataproc cluster. Move your HDFS data into larger HDD disks to save on storage costs.
D. Create a Cloud Dataproc cluster on Google Cloud Platform, and then migrate your Hadoop code objects to the new cluster. Move your data to Cloud Storage and leverage the Cloud Dataproc connector to run jobs on that data.
You are developing a web application that contains private images and videos stored in a Cloud Storage bucket. Your users are anonymous and do not have Google Accounts. You want to use your application-specific logic to control access to the images and videos. How should you configure access?
A. Cache each web application user's IP address to create a named IP table using Google Cloud Armor. Create a Google Cloud Armor security policy that allows users to access the backend bucket.
B. Grant the Storage Object Viewer IAM role to allUsers. Allow users to access the bucket after authenticating through your web application.
C. Configure Identity-Aware Proxy (IAP) to authenticate users into the web application. Allow users to access the bucket after authenticating through IAP.
D. Generate a signed URL that grants read access to the bucket. Allow users to access the URL after authenticating through your web application.
In some scenarios, you might not want to require your users to have a Google account in order to access Cloud Storage, but you still want to control access using your application-specific logic. The typical way to address this use case is to provide a signed URL to a user, which gives the user read, write, or delete access to that resource for a limited time. You specify an expiration time when you create the signed URL. Anyone who knows the URL can access the resource until the expiration time for the URL is reached or the key used to sign the URL is rotated.
| Page 9 out of 22 Pages |
| Previous |