Topic 2: Misc. Questions
You support an application that uses the Cloud Storage API. You review the logs and discover multiple HTTP 503 Service Unavailable error responses from the API. Your application logs the error and does not take any further action. You want to implement Google-recommended retry logic to improve success rates. Which approach should you take?
A. Retry the failures in batch after a set number of failures is logged
B. Retry each failure at a set time interval up to a maximum number of times.
C. Retry each failure at increasing time intervals up to a maximum number of tries.
D. Retry each failure at decreasing time intervals up to a maximum number of tries
You are monitoring a web application that is written in Go and deployed in Google Kubernetes Engine. You notice an increase in CPU and memory utilization. You need to determine which source code is consuming the most CPU and memory resources. What should you do?
A. Download, install, and start the Snapshot Debugger agent in your VM. Take debug snapshots of the functions that take the longest time. Review the call stack frame, and identify the local variables at that level in the stack.
B. Import the Cloud Profiler package into your application, and initialize the Profiler agent. Review the generated flame graph in the Google Cloud console to identify time-intensive functions.
C. Import OpenTelemetry and Trace export packages into your application, and create the trace provider. Review the latency data for your application on the Trace overview page, and identify where bottlenecks are occurring.
D. Create a Cloud Logging query that gathers the web application's logs. Write a Python script that calculates the difference between the timestamps from the beginning and the end of the application's longest functions to identity time-intensive functions.
You are developing a new application that has the following design requirements: Creation and changes to the application infrastructure are versioned and auditable. The application and deployment infrastructure uses Google-managed services as much as possible. The application runs on a serverless compute platform. How should you design the application’s architecture?
A. 1. Store the application and infrastructure source code in a Git repository.
2. Use Cloud Build to deploy the application infrastructure with Terraform.
3. Deploy the application to a Cloud Function as a pipeline step.
B. 1. Deploy Jenkins from the Google Cloud Marketplace, and define a continuous integration
pipeline in Jenkins.
2. Configure a pipeline step to pull the application source code from a Git repository.
3. Deploy the application source code to App Engine as a pipeline step.
C. 1. Create a continuous integration pipeline on Cloud Build, and configure the pipeline to
deploy the application infrastructure using Deployment Manager templates.
2. Configure a pipeline step to create a container with the latest application source code.
3. Deploy the container to a Compute Engine instance as a pipeline step.
D. 1. Deploy the application infrastructure using gcloud commands.
2. Use Cloud Build to define a continuous integration pipeline for changes to the application
source code.
3. Configure a pipeline step to pull the application source code from a Git repository, and
create a containerized application.
4. Deploy the new container on Cloud Run as a pipeline step.
You are developing an application that will handle requests from end users. You need to secure a Cloud Function called by the application to allow authorized end users to authenticate to the function via the application while restricting access to unauthorized users. You will integrate Google Sign-In as part of the solution and want to follow Google recommended best practices. What should you do?
A. Deploy from a source code repository and grant users the roles/cloudfunctions.viewer role.
B. Deploy from a source code repository and grant users the roles/cloudfunctions.invoker role
C. Deploy from your local machine using gcloud and grant users the roles/cloudfunctions.admin role
D. Deploy from your local machine using gcloud and grant users the roles/cloudfunctions.developer role
This architectural diagram depicts a system that streams data from thousands of devices. You want to ingest data into a pipeline, store the data, and analyze the data using SQL statements. Which Google Cloud services should you use for steps 1, 2, 3, and 4?
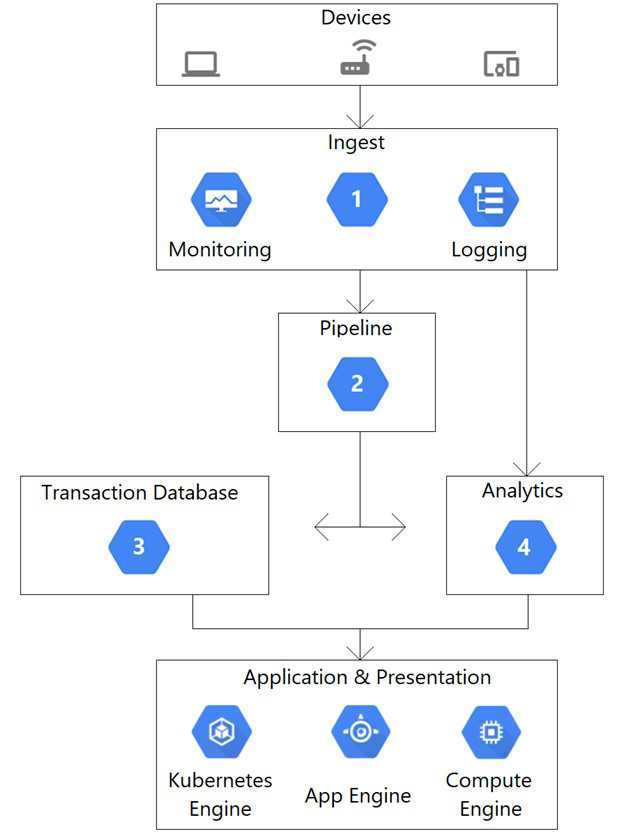
A. 1) App Engine
2) Pub/Sub
3) BigQuery
4) Firestore
B. 1) Dataflow
2) Pub/Sub
3) Firestore
4) BigQuery
C. 1) Pub/Sub
2) Dataflow
3) BigQuery
4) Firestore
D. 1) Pub/Sub
2) Dataflow
3) Firestore
4) BigQuery
You are using Cloud Run to host a global ecommerce web application. Your company's design team is creating a new color scheme for the web app. You have been tasked with determining whether the new color scheme will increase sales You want to conduct testing on live production traffic How should you design the study?
A. Use an external HTTP(S) load balancer to route a predetermined percentage of traffic to two different color schemes of your application Analyze the results to determine whether there is a statistically significant difference in sales.
B. Use an external HTTP(S) load balancer to route traffic to the original color scheme while the new deployment is created and tested After testing is complete reroute all traffic to the new color scheme Analyze the results to determine whether there is a statistically significant difference in sales.
C. Enable a feature flag that displays the new color scheme to half of all users. Monitor sales to see whether they increase for this group of users.
D. Use an external HTTP(S) load balancer to mirror traffic to the new version of your application Analyze the results to determine whether there is a statistically significant difference in sales.
You have been tasked with planning the migration of your company’s application from onpremises to Google Cloud. Your company’s monolithic application is an ecommerce website. The application will be migrated to microservices deployed on Google Cloud in stages. The majority of your company’s revenue is generated through online sales, so it is important to minimize risk during the migration. You need to prioritize features and select the first functionality to migrate. What should you do?
A. Migrate the Product catalog, which has integrations to the frontend and product database.
B. Migrate Payment processing, which has integrations to the frontend, order database, and third-party payment vendor.
C. Migrate Order fulfillment, which has integrations to the order database, inventory system, and third-party shipping vendor.
D. Migrate the Shopping cart, which has integrations to the frontend, cart database, inventory system, and payment processing system.
You need to configure a Deployment on Google Kubernetes Engine (GKE). You want to include a check that verifies that the containers can connect to the database. If the Pod is failing to connect, you want a script on the container to run to complete a graceful shutdown. How should you configure the Deployment?
A. Create two jobs: one that checks whether the container can connect to the database, and another that runs the shutdown script if the Pod is failing.
B. Create the Deployment with a livenessProbe for the container that will fail if the container can't connect to the database. Configure a Prestop lifecycle handler that runs the shutdown script if the container is failing.
C. Create the Deployment with a PostStart lifecycle handler that checks the service availability. Configure a PreStop lifecycle handler that runs the shutdown script if the container is failing.
D. Create the Deployment with an initContainer that checks the service availability. Configure a Prestop lifecycle handler that runs the shutdown script if the Pod is failing.
You have deployed a Java application to Cloud Run. Your application requires access to a database hosted on Cloud SQL Due to regulatory requirements: your connection to the Cloud SQL instance must use its internal IP address. How should you configure the connectivity while following Google-recommended best practices'?
A. Configure your Cloud Run service with a Cloud SQL connection.
B. Configure your Cloud Run service to use a Serverless VPC Access connector
C. Configure your application to use the Cloud SQL Java connector
D. Configure your application to connect to an instance of the Cloud SQL Auth proxy
You have a container deployed on Google Kubernetes Engine. The container can sometimes be slow to launch, so you have implemented a liveness probe. You notice that the liveness probe occasionally fails on launch. What should you do?
A. Add a startup probe.
B. Increase the initial delay for the liveness probe.
C. Increase the CPU limit for the container.
D. Add a readiness probe.
You are a developer working with the CI/CD team to troubleshoot a new feature that your team introduced. The CI/CD team used HashiCorp Packer to create a new Compute Engine image from your development branch. The image was successfully built, but is not booting up. You need to investigate the issue with the CI/CD team. What should you do?
A. Create a new feature branch, and ask the build team to rebuild the image.
B. Shut down the deployed virtual machine, export the disk, and then mount the disk locally to access the boot logs.
C. Install Packer locally, build the Compute Engine image locally, and then run it in your personal Google Cloud project.
D. Check Compute Engine OS logs using the serial port, and check the Cloud Logging logs to confirm access to the serial port.
Your team is developing a new application using a PostgreSQL database and Cloud Run. You are responsible for ensuring that all traffic is kept private on Google Cloud. You want to use managed services and follow Google-recommended best practices. What should you do?
A. 1. Enable Cloud SQL and Cloud Run in the same project.
2. Configure a private IP address for Cloud SQL. Enable private services access.
3. Create a Serverless VPC Access connector.
4. Configure Cloud Run to use the connector to connect to Cloud SQL.
B. 1. Install PostgreSQL on a Compute Engine virtual machine (VM), and enable Cloud Run in
the same project.
2. Configure a private IP address for the VM. Enable private services access.
3. Create a Serverless VPC Access connector.
4. Configure Cloud Run to use the connector to connect to the VM hosting PostgreSQL.
C. 1. Use Cloud SQL and Cloud Run in different projects.
2. Configure a private IP address for Cloud SQL. Enable private services access.
3. Create a Serverless VPC Access connector.
4. Set up a VPN connection between the two projects. Configure Cloud Run to use the
connector to connect to Cloud SQL.
D. 1. Install PostgreSQL on a Compute Engine VM, and enable Cloud Run in different
projects.
2. Configure a private IP address for the VM. Enable private services access.
3. Create a Serverless VPC Access connector.
4. Set up a VPN connection between the two projects. Configure Cloud Run to use the
connector to access the VM hosting PostgreSQL
| Page 6 out of 22 Pages |
| 3456789 |
| Professional-Cloud-Developer Practice Test Home |
Real-World Scenario Mastery: Our Professional-Cloud-Developer practice exam don't just test definitions. They present you with the same complex, scenario-based problems you'll encounter on the actual exam.
Strategic Weakness Identification: Each practice session reveals exactly where you stand. Discover which domains need more attention, before Google Certified Professional - Cloud Developer exam day arrives.
Confidence Through Familiarity: There's no substitute for knowing what to expect. When you've worked through our comprehensive Professional-Cloud-Developer practice exam questions pool covering all topics, the real exam feels like just another practice session.
Copyright © All Rights Reserved