Topic 2: Misc. Questions
Your team develops services that run on Google Cloud. You want to process messages sent to a Pub/Sub topic, and then store them. Each message must be processed exactly once to avoid duplication of data and any data conflicts. You need to use the cheapest and most simple solution. What should you do?
A. Process the messages with a Dataproc job, and write the output to storage.
B. Process the messages with a Dataflow streaming pipeline using Apache Beam's PubSubIO package, and write the output to storage.
C. Process the messages with a Cloud Function, and write the results to a BigQuery location where you can run a job to deduplicate the data.
D. Retrieve the messages with a Dataflow streaming pipeline, store them in Cloud Bigtable, and use another Dataflow streaming pipeline to deduplicate messages.
You are designing a deployment technique for your new applications on Google Cloud. As part of your deployment planning, you want to use live traffic to gather performance metrics for both new and existing applications. You need to test against the full production load prior to launch. What should you do?
A. Use canary deployment
B. Use blue/green deployment
C. Use rolling updates deployment
D. Use A/B testing with traffic mirroring during deployment
You are building a mobile application that will store hierarchical data structures in a database. The application will enable users working offline to sync changes when they are back online. A backend service will enrich the data in the database using a service account. The application is expected to be very popular and needs to scale seamlessly and securely. Which database and IAM role should you use?
A. Use Cloud SQL, and assign the roles/cloudsql.editor role to the service account
B. Use Bigtable, and assign the roles/bigtable.viewer role to the service account.
C. Use Firestore in Native mode and assign the roles/datastore.user role to the service account.
D. Use Firestore in Datastore mode and assign the roles/datastore.viewer role to the service account.
Cloud Firestore supports offline data persistence. This feature caches a copy of the Cloud Firestore data that your app is actively using, so your app can access the data when the device is offline. You can write, read, listen to, and query the cached data. When the device comes back online, Cloud Firestore synchronizes any local changes made by your app to the Cloud Firestore backend.
Your operations team has asked you to create a script that lists the Cloud Bigtable, Memorystore, and Cloud SQL databases running within a project. The script should allow users to submit a filter expression to limit the results presented. How should you retrieve the data?
A. Use the HBase API, Redis API, and MySQL connection to retrieve database lists. Combine the results, and then apply the filter to display the results
B. Use the HBase API, Redis API, and MySQL connection to retrieve database lists. Filter the results individually, and then combine them to display the results
C. Run gcloud bigtable instances list, gcloud redis instances list, and gcloud sql databases list. Use a filter within the application, and then display the results
D. Run gcloud bigtable instances list, gcloud redis instances list, and gcloud sql databases list. Use --filter flag with each command, and then display the results
You are developing an application that consists of several microservices running in a Google Kubernetes Engine cluster. One microservice needs to connect to a third-party database running on-premises. You need to store credentials to the database and ensure that these credentials can be rotated while following security best practices. What should you do?
A. Store the credentials in a sidecar container proxy, and use it to connect to the third-party database.
B. Configure a service mesh to allow or restrict traffic from the Pods in your microservice to the database.
C. Store the credentials in an encrypted volume mount, and associate a Persistent Volume Claim with the client Pod.
D. Store the credentials as a Kubernetes Secret, and use the Cloud Key Management Service plugin to handle encryption and decryption.
By default, Google Kubernetes Engine (GKE) encrypts customer content stored at rest,
including Secrets. GKE handles and manages this default encryption for you without any
additional action on your part.
Application-layer secrets encryption provides an additional layer of security for sensitive
data, such as Secrets, stored in etc. Using this functionality, you can use a key managed
with Cloud KMS to encrypt data at the application layer. This encryption protects against
attackers who gain access to an offline copy of etc.
You want to create “fully baked” or “golden” Compute Engine images for your application. You need to bootstrap your application to connect to the appropriate database according to the environment the application is running on (test, staging, production). What should you do?
A. Embed the appropriate database connection string in the image. Create a different image for each environment.
B. When creating the Compute Engine instance, add a tag with the name of the database to be connected. In your application, query the Compute Engine API to pull the tags for the current instance, and use the tag to construct the appropriate database connection string.
C. When creating the Compute Engine instance, create a metadata item with a key of “DATABASE” and a value for the appropriate database connection string. In your application, read the “DATABASE” environment variable, and use the value to connect to the appropriate database.
D. When creating the Compute Engine instance, create a metadata item with a key of “DATABASE” and a value for the appropriate database connection string. In your application, query the metadata server for the “DATABASE” value, and use the value to connect to the appropriate database.
You are deploying a microservices application to Google Kubernetes Engine (GKE) that will
broadcast livestreams. You expect unpredictable traffic patterns and large variations in the
number of concurrent users. Your application must meet the following requirements:
A. Distribute your workload evenly using a multi-zonal node pool.
B. Distribute your workload evenly using multiple zonal node pools.
C. Use cluster autoscaler to resize the number of nodes in the node pool, and use a Horizontal Pod Autoscaler to scale the workload.
D. Create a managed instance group for Compute Engine with the cluster nodes. Configure autoscaling rules for the managed instance group.
E. Create alerting policies in Cloud Monitoring based on GKE CPU and memory utilization. Ask an on-duty engineer to scale the workload by executing a script when CPU and memory usage exceed predefined thresholds.
Your application is controlled by a managed instance group. You want to share a large read-only data set between all the instances in the managed instance group. You want to ensure that each instance can start quickly and can access the data set via its filesystem with very low latency. You also want to minimize the total cost of the solution. What should you do?
A. Move the data to a Cloud Storage bucket, and mount the bucket on the filesystem using Cloud Storage FUSE.
B. Move the data to a Cloud Storage bucket, and copy the data to the boot disk of the instance via a startup script.
C. Move the data to a Compute Engine persistent disk, and attach the disk in read-only mode to multiple Compute Engine virtual machine instances.
D. Move the data to a Compute Engine persistent disk, take a snapshot, create multiple disks from the snapshot, and attach each disk to its own instance.
Your organization has recently begun an initiative to replatform their legacy applications onto Google Kubernetes Engine. You need to decompose a monolithic application into microservices. Multiple instances have read and write access to a configuration file, which is stored on a shared file system. You want to minimize the effort required to manage this transition, and you want to avoid rewriting the application code. What should you do?
A. Create a new Cloud Storage bucket, and mount it via FUSE in the container.
B. Create a new persistent disk, and mount the volume as a shared PersistentVolume.
C. Create a new Filestore instance, and mount the volume as an NFS PersistentVolume.
D. Create a new ConfigMap and volumeMount to store the contents of the configuration file.
ConfigMaps bind non-sensitive configuration artifacts such as configuration files,
command-line arguments, and environment variables to your Pod containers and system
components at runtime.
A ConfigMap separates your configurations from your Pod and components, which helps
keep your workloads portable. This makes their configurations easier to change and
manage, and prevents hardcoding configuration data to Pod specifications.
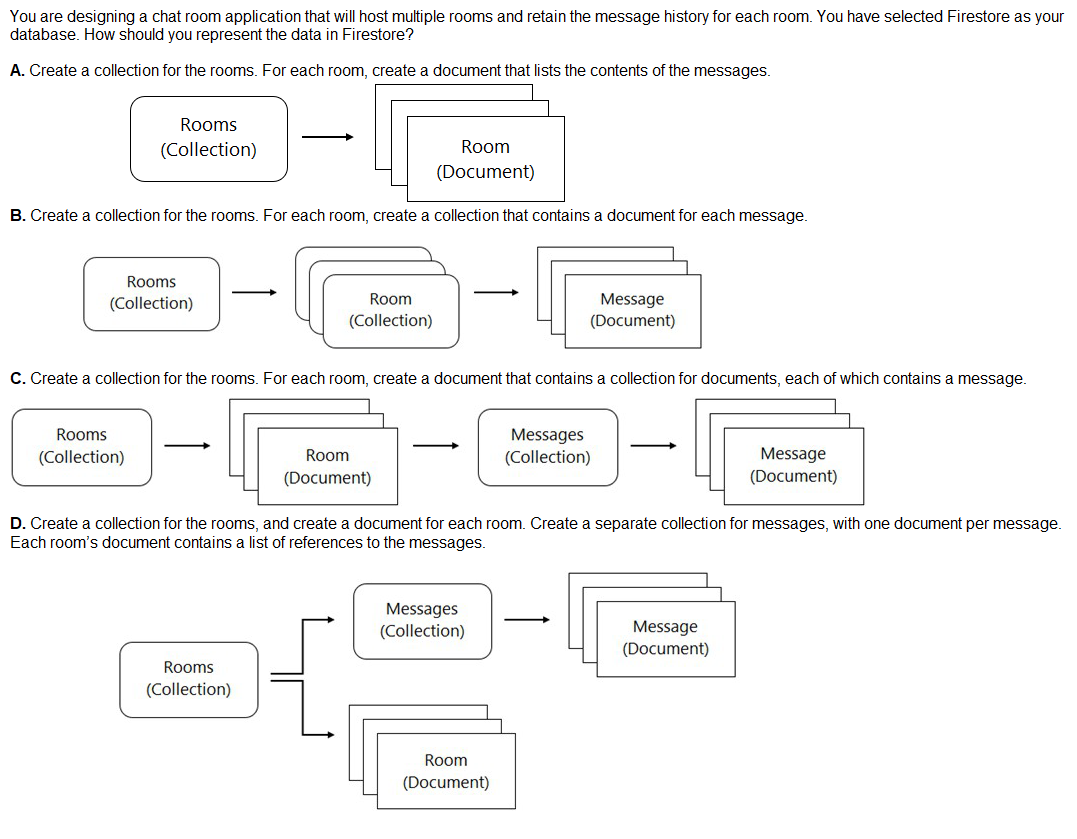
A. Option A
B. Option B
C. Option C
D. Option D
You are running a web application on Google Kubernetes Engine that you inherited. You want to determine whether the application is using libraries with known vulnerabilities or is vulnerable to XSS attacks. Which service should you use?
A. Google Cloud Armor
B. Debugger
C. Web Security Scanner
D. Error Reporting
Web Security Scanner identifies security vulnerabilities in your App Engine, Google Kubernetes Engine (GKE), and Compute Engine web applications. It crawls your application, following all links within the scope of your starting URLs, and attempts to exercise as many user inputs and event handlers as possible.
The new version of your containerized application has been tested and is ready to deploy to production on Google Kubernetes Engine. You were not able to fully load-test the new version in pre-production environments, and you need to make sure that it does not have performance problems once deployed. Your deployment must be automated. What should you do?
A. Use Cloud Load Balancing to slowly ramp up traffic between versions. Use Cloud Monitoring to look for performance issues.
B. Deploy the application via a continuous delivery pipeline using canary deployments. Use Cloud Monitoring to look for performance issues. and ramp up traffic as the metrics support it.
C. Deploy the application via a continuous delivery pipeline using blue/green deployments. Use Cloud Monitoring to look for performance issues, and launch fully when the metrics support it.
D. Deploy the application using kubectl and set the spec.updateStrategv.type to RollingUpdate. Use Cloud Monitoring to look for performance issues, and run the kubectl rollback command if there are any issues.
| Page 3 out of 22 Pages |
| 1234567 |
| Professional-Cloud-Developer Practice Test Home |
Real-World Scenario Mastery: Our Professional-Cloud-Developer practice exam don't just test definitions. They present you with the same complex, scenario-based problems you'll encounter on the actual exam.
Strategic Weakness Identification: Each practice session reveals exactly where you stand. Discover which domains need more attention, before Google Certified Professional - Cloud Developer exam day arrives.
Confidence Through Familiarity: There's no substitute for knowing what to expect. When you've worked through our comprehensive Professional-Cloud-Developer practice exam questions pool covering all topics, the real exam feels like just another practice session.
Copyright © All Rights Reserved