A large consumer goods manufacturer has the following products on sale
• 34 different toothpaste variants
• 48 different toothbrush variants
• 43 different mouthwash variants
The entire sales history of all these products is available in Amazon S3 Currently, the
company is using custom-built autoregressive integrated moving average (ARIMA) models
to forecast demand for these products The company wants to predict the demand for a new
product that will soon be launched.
Which solution should a Machine Learning Specialist apply?
A. Train a custom ARIMA model to forecast demand for the new product.
B. Train an Amazon SageMaker DeepAR algorithm to forecast demand for the new product
C. Train an Amazon SageMaker k-means clustering algorithm to forecast demand for the new product.
D. Train a custom XGBoost model to forecast demand for the new product
Explanation:
The company wants to predict the demand for a new product that will soon be
launched, based on the sales history of similar products. This is a time series
forecasting problem, which requires a machine learning algorithm that can learn
from historical data and generate future predictions.
One of the most suitable solutions for this problem is to use the Amazon
SageMaker DeepAR algorithm, which is a supervised learning algorithm for
forecasting scalar time series using recurrent neural networks (RNN). DeepAR can
handle multiple related time series, such as the sales of different products, and
learn a global model that captures the common patterns and trends across the
time series. DeepAR can also generate probabilistic forecasts that provide
confidence intervals and quantify the uncertainty of the predictions.
DeepAR can outperform traditional forecasting methods, such as ARIMA,
especially when the dataset contains hundreds or thousands of related time series.
DeepAR can also use the trained model to forecast the demand for new products
that are similar to the ones it has been trained on, by using the categorical features
that encode the product attributes. For example, the company can use the product
type, brand, flavor, size, and price as categorical features to group the products
and learn the typical behavior for each group.
Therefore, the Machine Learning Specialist should apply the Amazon SageMaker
DeepAR algorithm to forecast the demand for the new product, by using the sales
history of the existing products as the training dataset, and the product attributes
as the categorical features.
A Machine Learning Specialist is working with a large company to leverage machine learning within its products. The company wants to group its customers into categories based on which customers will and will not churn within the next 6 months. The company has labeled the data available to the Specialist. Which machine learning model type should the Specialist use to accomplish this task?
A. Linear regression
B. Classification
C. Clustering
D. Reinforcement learning
Explanation:
The goal of classification is to determine to which class or category a data point (customer
in our case) belongs to. For classification problems, data scientists would use historical
data with predefined target variables AKA labels (churner/non-churner) – answers that
need to be predicted – to train an algorithm. With classification, businesses can answer the
following questions:
Will this customer churn or not?
Will a customer renew their subscription?
Will a user downgrade a pricing plan?
Are there any signs of unusual customer behavior?
A media company is building a computer vision model to analyze images that are on social media. The model consists of CNNs that the company trained by using images that the
company stores in Amazon S3. The company used an Amazon SageMaker training job in
File mode with a single Amazon EC2 On-Demand Instance.
Every day, the company updates the model by using about 10,000 images that the
company has collected in the last 24 hours. The company configures training with only one
epoch. The company wants to speed up training and lower costs without the need to make
any code changes.
Which solution will meet these requirements?
A. Instead of File mode, configure the SageMaker training job to use Pipe mode. Ingest the data from a pipe.
B. Instead Of File mode, configure the SageMaker training job to use FastFile mode with no Other changes.
C. Instead Of On-Demand Instances, configure the SageMaker training job to use Spot Instances. Make no Other changes.
D. Instead Of On-Demand Instances, configure the SageMaker training job to use Spot Instances. Implement model checkpoints.
Explanation: The solution C will meet the requirements because it uses Amazon
SageMaker Spot Instances, which are unused EC2 instances that are available at up to
90% discount compared to On-Demand prices. Amazon SageMaker Spot Instances can
speed up training and lower costs by taking advantage of the spare EC2 capacity. The
company does not need to make any code changes to use Spot Instances, as it can simply
enable the managed spot training option in the SageMaker training job configuration. The
company also does not need to implement model checkpoints, as it is using only one
epoch for training, which means the model will not resume from a previous state1.
The other options are not suitable because:
Option A: Configuring the SageMaker training job to use Pipe mode instead of File
mode will not speed up training or lower costs significantly. Pipe mode is a data
ingestion mode that streams data directly from S3 to the training algorithm, without
copying the data to the local storage of the training instance. Pipe mode can
reduce the startup time of the training job and the disk space usage, but it does not
affect the computation time or the instance price. Moreover, Pipe mode may
require some code changes to handle the streaming data, depending on the
training algorithm2.
Option B: Configuring the SageMaker training job to use FastFile mode instead of
File mode will not speed up training or lower costs significantly. FastFile mode is a
data ingestion mode that copies data from S3 to the local storage of the training
instance in parallel with the training process. FastFile mode can reduce the startup
time of the training job and the disk space usage, but it does not affect the
computation time or the instance price. Moreover, FastFile mode is only available
for distributed training jobs that use multiple instances, which is not the case for
the company3.
Option D: Configuring the SageMaker training job to use Spot Instances and
implementing model checkpoints will not meet the requirements without the need
to make any code changes. Model checkpoints are a feature that allows the
training job to save the model state periodically to S3, and resume from the latest
checkpoint if the training job is interrupted. Model checkpoints can help to avoid
losing the training progress and ensure the model convergence, but they require
some code changes to implement the checkpointing logic and the resuming logic4.
A social media company wants to develop a machine learning (ML) model to detect
Inappropriate or offensive content in images. The company has collected a large dataset of
labeled images and plans to use the built-in Amazon SageMaker image classification
algorithm to train the model. The company also intends to use SageMaker pipe mode to
speed up the training.
...company splits the dataset into training, validation, and testing datasets. The company
stores the training and validation images in folders that are named Training and Validation,
respectively. The folder ...ain subfolders that correspond to the names of the dataset
classes. The company resizes the images to the same sue and generates two input
manifest files named training.1st and validation.1st, for the ..ing dataset and the validation
dataset. respectively. Finally, the company creates two separate Amazon S3 buckets for
uploads of the training dataset and the validation dataset.
...h additional data preparation steps should the company take before uploading the files to
Amazon S3?
A. Generate two Apache Parquet files, training.parquet and validation.parquet. by reading the images into a Pandas data frame and storing the data frame as a Parquet file. Upload the Parquet files to the training S3 bucket
B. Compress the training and validation directories by using the Snappy compression library Upload the manifest and compressed files to the training S3 bucket
C. Compress the training and validation directories by using the gzip compression library. Upload the manifest and compressed files to the training S3 bucket.
D. Generate two RecordIO files, training rec and validation.rec. from the manifest files by using the im2rec Apache MXNet utility tool. Upload the RecordlO files to the training S3 bucket.
Explanation: The SageMaker image classification algorithm supports both RecordIO and image content types for training in file mode, and supports the RecordIO content type for training in pipe mode1. However, the algorithm also supports training in pipe mode using the image files without creating RecordIO files, by using the augmented manifest format2. In this case, the company should generate.
A company’s data scientist has trained a new machine learning model that performs better
on test data than the company’s existing model performs in the production environment.
The data scientist wants to replace the existing model that runs on an Amazon SageMaker
endpoint in the production environment. However, the company is concerned that the new
model might not work well on the production environment data.
The data scientist needs to perform A/B testing in the production environment to evaluate
whether the new model performs well on production environment data.
Which combination of steps must the data scientist take to perform the A/B testing?
(Choose two.)
A. Create a new endpoint configuration that includes a production variant for each of the two models.
B. Create a new endpoint configuration that includes two target variants that point to different endpoints.
C. Deploy the new model to the existing endpoint.
D. Update the existing endpoint to activate the new model.
E. Update the existing endpoint to use the new endpoint configuration.
Explanation: The combination of steps that the data scientist must take to perform the A/B
testing are to create a new endpoint configuration that includes a production variant for
each of the two models, and update the existing endpoint to use the new endpoint
configuration. This approach will allow the data scientist to deploy both models on the
same endpoint and split the inference traffic between them based on a specified
distribution.
Amazon SageMaker is a fully managed service that provides developers and data
scientists the ability to quickly build, train, and deploy machine learning models. Amazon
SageMaker supports A/B testing on machine learning models by allowing the data scientist
to run multiple production variants on an endpoint. A production variant is a version of a
model that is deployed on an endpoint. Each production variant has a name, a machine
learning model, an instance type, an initial instance count, and an initial weight. The initial
weight determines the percentage of inference requests that the variant will handle. For
example, if there are two variants with weights of 0.5 and 0.5, each variant will handle 50%
of the requests. The data scientist can use production variants to test models that have
been trained using different training datasets, algorithms, and machine learning
frameworks; test how they perform on different instance types; or a combination of all of the
above1.
To perform A/B testing on machine learning models, the data scientist needs to create a
new endpoint configuration that includes a production variant for each of the two models.
An endpoint configuration is a collection of settings that define the properties of an
endpoint, such as the name, the production variants, and the data capture configuration.
The data scientist can use the Amazon SageMaker console, the AWS CLI, or the AWS
SDKs to create a new endpoint configuration. The data scientist needs to specify the name,
model name, instance type, initial instance count, and initial variant weight for each
production variant in the endpoint configuration2.
After creating the new endpoint configuration, the data scientist needs to update the
existing endpoint to use the new endpoint configuration. Updating an endpoint is the
process of deploying a new endpoint configuration to an existing endpoint. Updating an
endpoint does not affect the availability or scalability of the endpoint, as Amazon
SageMaker creates a new endpoint instance with the new configuration and switches the
DNS record to point to the new instance when it is ready. The data scientist can use the
Amazon SageMaker console, the AWS CLI, or the AWS SDKs to update an endpoint. The
data scientist needs to specify the name of the endpoint and the name of the new endpoint
configuration to update the endpoint3.
The other options are either incorrect or unnecessary. Creating a new endpoint
configuration that includes two target variants that point to different endpoints is not
possible, as target variants are only used to invoke a specific variant on an endpoint, not to
define an endpoint configuration. Deploying the new model to the existing endpoint would
replace the existing model, not run it side-by-side with the new model. Updating the
existing endpoint to activate the new model is not a valid operation, as there is no
activation parameter for an endpoint.
A retail company is ingesting purchasing records from its network of 20,000 stores to Amazon S3 by using Amazon Kinesis Data Firehose. The company uses a small, serverbased application in each store to send the data to AWS over the internet. The company uses this data to train a machine learning model that is retrained each day. The company's data science team has identified existing attributes on these records that could be combined to create an improved model. Which change will create the required transformed records with the LEAST operational overhead?
A. Create an AWS Lambda function that can transform the incoming records. Enable data transformation on the ingestion Kinesis Data Firehose delivery stream. Use the Lambda function as the invocation target.
B. Deploy an Amazon EMR cluster that runs Apache Spark and includes the transformation logic. Use Amazon EventBridge (Amazon CloudWatch Events) to schedule an AWS Lambda function to launch the cluster each day and transform the records that accumulate in Amazon S3. Deliver the transformed records to Amazon S3.
C. Deploy an Amazon S3 File Gateway in the stores. Update the in-store software to deliver data to the S3 File Gateway. Use a scheduled daily AWS Glue job to transform the data that the S3 File Gateway delivers to Amazon S3.
D. Launch a fleet of Amazon EC2 instances that include the transformation logic. Configure the EC2 instances with a daily cron job to transform the records that accumulate in Amazon S3. Deliver the transformed records to Amazon S3.
Explanation: The solution A will create the required transformed records with the least
operational overhead because it uses AWS Lambda and Amazon Kinesis Data Firehose,
which are fully managed services that can provide the desired functionality. The solution A
involves the following steps:
Create an AWS Lambda function that can transform the incoming records. AWS
Lambda is a service that can run code without provisioning or managing
servers. AWS Lambda can execute the transformation logic on the purchasing
records and add the new attributes to the records1.
Enable data transformation on the ingestion Kinesis Data Firehose delivery
stream. Use the Lambda function as the invocation target. Amazon Kinesis Data
Firehose is a service that can capture, transform, and load streaming data into
AWS data stores. Amazon Kinesis Data Firehose can enable data transformation
and invoke the Lambda function to process the incoming records before delivering
them to Amazon S3. This can reduce the operational overhead of managing the
transformation process and the data storage2.
The other options are not suitable because:
Option B: Deploying an Amazon EMR cluster that runs Apache Spark and includes
the transformation logic, using Amazon EventBridge (Amazon CloudWatch
Events) to schedule an AWS Lambda function to launch the cluster each day and
transform the records that accumulate in Amazon S3, and delivering the
transformed records to Amazon S3 will incur more operational overhead than
using AWS Lambda and Amazon Kinesis Data Firehose. The company will have to
manage the Amazon EMR cluster, the Apache Spark application, the AWS
Lambda function, and the Amazon EventBridge rule. Moreover, this solution will
introduce a delay in the transformation process, as it will run only once a day3.
Option C: Deploying an Amazon S3 File Gateway in the stores, updating the instore
software to deliver data to the S3 File Gateway, and using a scheduled daily
AWS Glue job to transform the data that the S3 File Gateway delivers to Amazon
S3 will incur more operational overhead than using AWS Lambda and Amazon
Kinesis Data Firehose. The company will have to manage the S3 File Gateway,
the in-store software, and the AWS Glue job. Moreover, this solution will introduce
a delay in the transformation process, as it will run only once a day4.
Option D: Launching a fleet of Amazon EC2 instances that include the
transformation logic, configuring the EC2 instances with a daily cron job to
transform the records that accumulate in Amazon S3, and delivering the
transformed records to Amazon S3 will incur more operational overhead than
using AWS Lambda and Amazon Kinesis Data Firehose. The company will have to
manage the EC2 instances, the transformation code, and the cron job. Moreover,
this solution will introduce a delay in the transformation process, as it will run only
once a day5.
A machine learning (ML) specialist wants to secure calls to the Amazon SageMaker
Service API. The specialist has configured Amazon VPC with a VPC interface endpoint for
the Amazon SageMaker Service API and is attempting to secure traffic from specific sets of
instances and IAM users. The VPC is configured with a single public subnet.
Which combination of steps should the ML specialist take to secure the traffic? (Choose two.)
A. Add a VPC endpoint policy to allow access to the IAM users.
B. Modify the users' IAM policy to allow access to Amazon SageMaker Service API calls only.
C. Modify the security group on the endpoint network interface to restrict access to the instances.
D. Modify the ACL on the endpoint network interface to restrict access to the instances.
E. Add a SageMaker Runtime VPC endpoint interface to the VPC.
Explanation: To secure calls to the Amazon SageMaker Service API, the ML specialist
should take the following steps:
The other options are not as effective or necessary as the steps above. Adding a VPC
endpoint policy to allow access to the IAM users is not required, as the IAM users can
already access the Amazon SageMaker Service API through the VPC interface endpoint.
Modifying the users’ IAM policy to allow access to Amazon SageMaker Service API calls
only is not sufficient, as it does not prevent unauthorized instances from accessing the VPC
interface endpoint. Modifying the ACL on the endpoint network interface to restrict access
to the instances is not possible, as network ACLs are associated with subnets, not network
interfaces3.
A company that manufactures mobile devices wants to determine and calibrate the appropriate sales price for its devices. The company is collecting the relevant data and is determining data features that it can use to train machine learning (ML) models. There are more than 1,000 features, and the company wants to determine the primary features that contribute to the sales price. Which techniques should the company use for feature selection? (Choose three.)
A. Data scaling with standardization and normalization
B. Correlation plot with heat maps
C. Data binning
D. Univariate selection
E. Feature importance with a tree-based classifier
F. Data augmentation
Explanation: Feature selection is the process of selecting a subset of extracted features
that are relevant and contribute to minimizing the error rate of a trained model. Some
techniques for feature selection are:
A manufacturing company asks its Machine Learning Specialist to develop a model that classifies defective parts into one of eight defect types. The company has provided roughly 100000 images per defect type for training During the injial training of the image classification model the Specialist notices that the validation accuracy is 80%, while the training accuracy is 90% It is known that human-level performance for this type of image classification is around 90%. What should the Specialist consider to fix this issue1?
A. A longer training time
B. Making the network larger
C. Using a different optimizer
D. Using some form of regularization
Explanation: Regularization is a technique that can be used to prevent overfitting and
improve model performance on unseen data. Overfitting occurs when the model learns the
training data too well and fails to generalize to new and unseen data. This can be seen in
the question, where the validation accuracy is lower than the training accuracy, and both
are lower than the human-level performance. Regularization is a way of adding some
constraints or penalties to the model to reduce its complexity and prevent it from
memorizing the training data. Some common forms of regularization for image
classification are:
A Machine Learning Specialist is using Amazon Sage Maker to host a model for a highly
available customer-facing application.
The Specialist has trained a new version of the model, validated it with historical data, and
now wants to deploy it to production To limit any risk of a negative customer experience,
the Specialist wants to be able to monitor the model and roll it back, if needed.
What is the SIMPLEST approach with the LEAST risk to deploy the model and roll it back,
if needed?
A. Create a SageMaker endpoint and configuration for the new model version. Redirect production traffic to the new endpoint by updating the client configuration. Revert traffic to the last version if the model does not perform as expected.
B. Create a SageMaker endpoint and configuration for the new model version. Redirect production traffic to the new endpoint by using a load balancer Revert traffic to the last version if the model does not perform as expected.
C. Update the existing SageMaker endpoint to use a new configuration that is weighted to send 5% of the traffic to the new variant. Revert traffic to the last version by resetting the weights if the model does not perform as expected.
D. Update the existing SageMaker endpoint to use a new configuration that is weighted to send 100% of the traffic to the new variant Revert traffic to the last version by resetting the weights if the model does not perform as expected.
Explanation: Updating the existing SageMaker endpoint to use a new configuration that is weighted to send 5% of the traffic to the new variant is the simplest approach with the least risk to deploy the model and roll it back, if needed. This is because SageMaker supports A/B testing, which allows the Specialist to compare the performance of different model variants by sending a portion of the traffic to each variant. The Specialist can monitor the metrics of each variant and adjust the weights accordingly. If the new variant does not perform as expected, the Specialist can revert traffic to the last version by resetting the weights to 100% for the old variant and 0% for the new variant. This way, the Specialist can deploy the model without affecting the customer experience and roll it back easily if needed.
A machine learning (ML) specialist needs to extract embedding vectors from a text series. The goal is to provide a ready-to-ingest feature space for a data scientist to develop downstream ML predictive models. The text consists of curated sentences in English. Many sentences use similar words but in different contexts. There are questions and answers among the sentences, and the embedding space must differentiate between them. Which options can produce the required embedding vectors that capture word context and sequential QA information? (Choose two.)
A. Amazon SageMaker seq2seq algorithm
B. Amazon SageMaker BlazingText algorithm in Skip-gram mode
C. Amazon SageMaker Object2Vec algorithm
D. Amazon SageMaker BlazingText algorithm in continuous bag-of-words (CBOW) mode
E. Combination of the Amazon SageMaker BlazingText algorithm in Batch Skip-gram mode with a custom recurrent neural network (RNN)
Explanation:
To capture word context and sequential QA information, the embedding vectors
need to consider both the order and the meaning of the words in the text.
Option B, Amazon SageMaker BlazingText algorithm in Skip-gram mode, is a valid
option because it can learn word embeddings that capture the semantic similarity
and syntactic relations between words based on their co-occurrence in a window
of words. Skip-gram mode can also handle rare words better than continuous bagof-
words (CBOW) mode1.
Option E, combination of the Amazon SageMaker BlazingText algorithm in Batch
Skip-gram mode with a custom recurrent neural network (RNN), is another valid
option because it can leverage the advantages of Skip-gram mode and also use
an RNN to model the sequential nature of the text. An RNN can capture the
temporal dependencies and long-term dependencies between words, which are
important for QA tasks2.
Option A, Amazon SageMaker seq2seq algorithm, is not a valid option because it
is designed for sequence-to-sequence tasks such as machine translation,
summarization, or chatbots. It does not produce embedding vectors for text series,
but rather generates an output sequence given an input sequence3.
Option C, Amazon SageMaker Object2Vec algorithm, is not a valid option because
it is designed for learning embeddings for pairs of objects, such as text-image,
text-text, or image-image. It does not produce embedding vectors for text series,
but rather learns a similarity function between pairs of objects4.
Option D, Amazon SageMaker BlazingText algorithm in continuous bag-of-words
(CBOW) mode, is not a valid option because it does not capture word context as
well as Skip-gram mode. CBOW mode predicts a word given its surrounding
words, while Skip-gram mode predicts the surrounding words given a
word. CBOW mode is faster and more suitable for frequent words, but Skip-gram
mode can learn more meaningful embeddings for rare words1.
For the given confusion matrix, what is the recall and precision of the model?
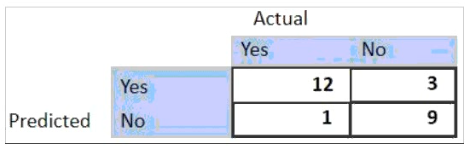
A. Recall = 0.92 Precision = 0.84
B. Recall = 0.84 Precision = 0.8
C. Recall = 0.92 Precision = 0.8
D. Recall = 0.8 Precision = 0.92
Explanation: Recall and precision are two metrics that can be used to evaluate the
performance of a classification model. Recall is the ratio of true positives to the total
number of actual positives, which measures how well the model can identify all the relevant
cases. Precision is the ratio of true positives to the total number of predicted positives,
which measures how accurate the model is when it makes a positive prediction. Based on
the confusion matrix in the image, we can calculate the recall and precision as follows:
Where TP is the number of true positives, FN is the number of false negatives, and FP is
the number of false positives. Therefore, the recall and precision of the model are 0.92 and
0.8, respectively.
| Page 1 out of 26 Pages |