Topic 6: Misc. Questions
Note: This question is part of a series of questions that present the same scenario.
Each question in the series contains a unique solution that might meet the stated
goals. Some question sets might have more than one correct solution, while others
might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a
result, these questions will not appear in the review screen.
You have two Azure SQL Database servers named Server1 and Server2. Each server
contains an Azure SQL database named Database1.
You need to restore Database1 from Server1 to Server2. The solution must replace the
existing Database1 on Server2.
Solution: You restore Database1 from Server1 to the Server2 by using the RESTORE
Transact-SQL command and the REPLACE option.
Does this meet the goal?
A. Yes
B. No
Explanation:
The goal is to restore a database from one server to another and replace the existing database with the same name on the target server. The RESTORE Transact-SQL command can be used to restore a .bacpac, .dacpac, or a backup file (.bak) from one Azure SQL server to another. When using the RESTORE command from a backup file stored in Azure Blob Storage, the REPLACE option is required if a database with the same name already exists on the target server. This option instructs SQL Server to overwrite the existing database, which meets the requirement to "replace the existing Database1 on Server2."
However, it’s important to note that in Azure SQL Database, cross-server restore from backup files requires the backup to be stored in Azure Blob Storage, and appropriate authentication (SAS or managed identity) must be configured. Assuming these prerequisites are satisfied, the RESTORE ... WITH REPLACE solution is valid.
Correct Option:
A. Yes
Reference:
Microsoft Docs - RESTORE (Transact-SQL) - REPLACE Option
You have an Azure SQL Database managed instance named SQLMI1. A Microsoft SQL
Server Agent job runs
on SQLMI1.
You need to ensure that an automatic email notification is sent once the job completes
What should you include in the solution?
A. From SQL Server Configuration Manager (SSMS), enable SQL Server Agent
B. From SQL Server Management Studio (SSMS), run sp_set_sqlagent_properties
C. From SQL Server Management Studio (SSMS), create a Database Mail profile
D. From the Azure portal, create an Azure Monitor action group that has an Email/SMS/Push/Voice action
Explanation:
SQL Server Agent on Azure SQL Managed Instance functions similarly to on-premises SQL Server but runs in a managed PaaS environment. To send email notifications for job completions, you must configure Database Mail within the Managed Instance, as this is the integrated email system for SQL Server. Creating a Database Mail profile and account (using an SMTP server) is a prerequisite before you can set up SQL Server Agent to use email notifications.
Correct Option:
C. From SQL Server Management Studio (SSMS), create a Database Mail profile.
This is the essential first step. You must create and test a Database Mail profile and account within SQLMI1 using T-SQL or SSMS. Once configured, you can then set this profile in SQL Server Agent properties and create job notifications (e.g., "When the job completes") to send emails to designated operators.
Incorrect Options:
A. From SQL Server Configuration Manager (SSMS), enable SQL Server Agent
SQL Server Configuration Manager is a Windows tool for on-premises SQL Server and is not accessible for Azure SQL Managed Instance, which is a fully managed PaaS service. Furthermore, SQL Server Agent is already enabled by default on Managed Instance; it doesn't need to be enabled via this method.
B. From SQL Server Management Studio (SSMS), run sp_set_sqlagent_properties
While sp_set_sqlagent_properties is a valid stored procedure to configure SQL Server Agent settings (like the mail profile), you must first have Database Mail configured. This procedure is a subsequent step, not the primary action to include. The core requirement is to set up the mail infrastructure first.
D. From the Azure portal, create an Azure Monitor action group that has an Email/SMS/Push/Voice action
Azure Monitor action groups are for Azure platform-level alerts (e.g., metric alerts, activity log alerts). They cannot be triggered directly by SQL Server Agent job completions, which are internal SQL Server events. SQL Agent notifications require Database Mail integration.
You have an Azure SQL Database managed instance named sqldbmi1 that contains a
database name Sales
You need to initiate a backup of Sales.
How should you complete the Transact-SQL statement? To answer, select the appropriate
options in the answer area.
NOTE: Each correct selection is worth one point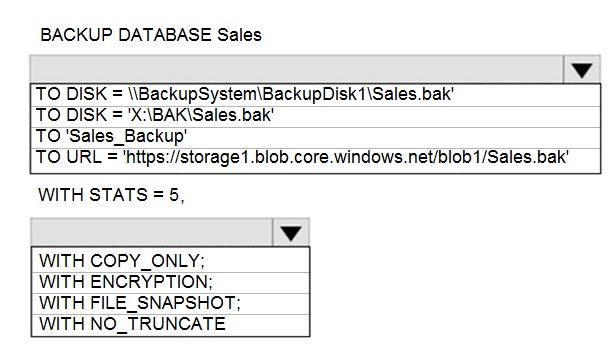
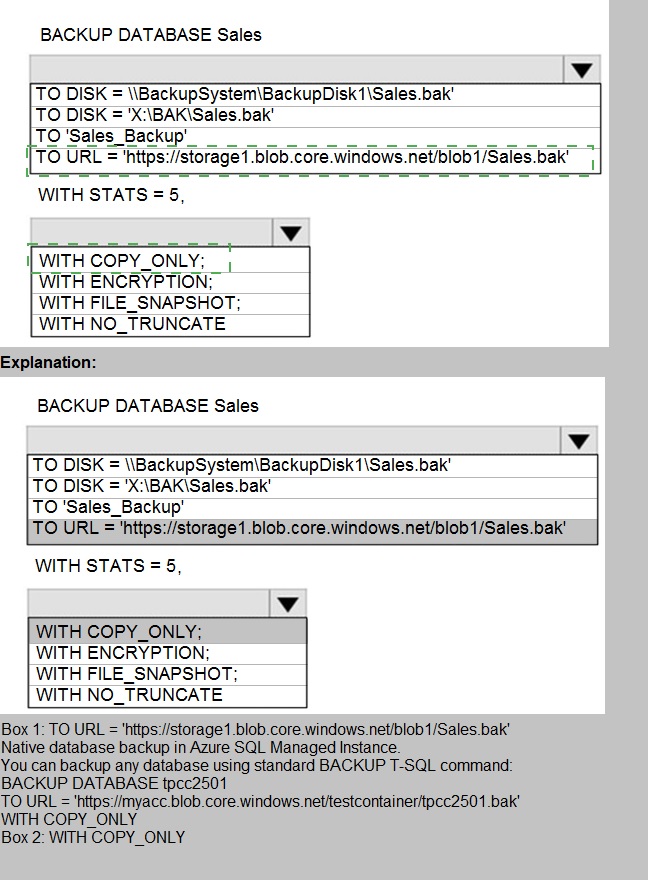
Explanation:
For an Azure SQL Database Managed Instance, the BACKUP DATABASE command is supported, but it must write to Azure Blob Storage (URL). Managed Instance does not support backing up to local disk (DISK =) or a local tape/device (TO 'device_name'). The backup URL must point to an Azure Storage blob container with appropriate SAS tokens or managed identity access configured.
Correct Selections:
TO URL = 'https://storage1.blob.core.windows.net/blob1/Sales.bak'
This is the only supported backup destination for Azure SQL Managed Instance. The backup file must be stored in an Azure Blob Storage container. The URL format must specify the full path to the .bak file within the container.
WITH COPY_ONLY;
A COPY_ONLY backup does not break the log backup chain and is ideal for taking ad-hoc backups for migration, testing, or other purposes without affecting regular backup schedules. Since this is a one-time "initiate a backup" request (not part of a scheduled sequence), COPY_ONLY is a safe and recommended option.
Incorrect Options:
Backup Destination (TO DISK, TO 'Sales_Backup'):
TO DISK = ...: Managed Instance cannot access on-premises or local network file shares (\\BackupSystem\...) or local drives (X:\BAK\...). Backups must go to Azure Blob Storage.
TO 'Sales_Backup': This syntax refers to a logical backup device predefined on the SQL Server instance. Managed Instance does not support creating or using logical backup devices for BACKUP commands.
WITH Options:
WITH ENCRYPTION: While Managed Instance can create encrypted backups, encryption requires specifying an encryption algorithm and encryptor (certificate or asymmetric key) in the WITH clause. Using ENCRYPTION alone without these specifics is invalid.
WITH FILE_SNAPSHOT: This option is used for Azure SQL Database (single database) automated backups when performing geo-replication/restore operations, not for Managed Instance BACKUP DATABASE commands.
WITH NO_TRUNCATE: This is used with BACKUP LOG to back up the tail of the log without truncating it, typically during a disaster recovery scenario. It is not applicable to a full database backup command.
Reference:Microsoft Docs - Backup to URL for SQL Server Managed Instance
You have an Azure SQL database.
You discover that the plan cache is full of compiled plans that were used only once.
You run the select * from sys.database_scoped_configurations Transact-SQL command
and receive the results shown in the following table You need relieve the memory pressure.
You need relieve the memory pressure.
What should you configure?
A. LEGACY_CARDINALITY_ESTIMATION
B. QUERY_OPTIMIZER_HOTFIXES
C. OPTIMIZE_FOR_AD_HOC_WORKLOADS
D. ACCELERATED_PLAN_FORCING
Explanation:
When the plan cache is filled with compiled plans used only once (a common symptom of ad-hoc workloads), it causes memory pressure because these single-use plans consume cache space without providing reuse benefits. The specific database-scoped configuration designed to mitigate this is OPTIMIZE_FOR_AD_HOC_WORKLOADS.
Correct Option:
C. OPTIMIZE_FOR_AD_HOC_WORKLOADS
Enabling this setting (value = 1) changes the caching behavior for single-use ad-hoc queries. Instead of storing the full compiled plan, SQL Server stores a smaller plan stub in the cache on the first compilation. Only if the same query is compiled again will the full plan be cached. This significantly reduces the memory footprint of the plan cache for ad-hoc workloads, directly relieving memory pressure.
Incorrect Options:
A. LEGACY_CARDINALITY_ESTIMATION
This setting controls whether the database uses the older SQL Server 2012 cardinality estimator (value = 1) or the newer, default estimator (value = 0). It affects query optimization and performance but does not address the caching behavior of single-use plans.
B. QUERY_OPTIMIZER_HOTFIXES
This setting determines whether the latest query optimizer hotfixes (trace flag 4199 behavior) are enabled at the database level. It influences plan generation but does not impact how or when plans are cached for ad-hoc queries.
D. ACCELERATED_PLAN_FORCING
This setting improves the performance of automatic plan forcing (Query Store forced plans) by caching a helper structure. It is related to Query Store plan forcing efficiency, not to reducing plan cache bloat from single-use ad-hoc queries.
Reference:
Microsoft Docs - optimize for ad hoc workloads Server Configuration Option
You are planning disaster recovery for the failover group of an Azure SQL Database
managed instance.
Your company’s SLA requires that the database in the failover group become available as
quickly as possible if a major outage occurs.
You set the Read/Write failover policy to Automatic.
What are two results of the configuration? Each correct answer presents a complete
solution.
NOTE: Each correct selection is worth one point.
A. In the event of a datacenter or Azure regional outage, the databases will fail over automatically.
B. In the event of an outage, the databases in the primary instance will fail over immediately.
C. In the event of an outage, you can selectively fail over individual databases.
D. In the event of an outage, you can set a different grace period to fail over each database.
E. In the event of an outage, the minimum delay for the databases to fail over in the primary instance will be one hour.
Explanation:
For an Azure SQL Database Managed Instance failover group with the Read/Write failover policy set to Automatic, failover is managed at the instance level (all databases together) and is triggered by Azure's health detection of a major outage. The configuration includes a built-in grace period to avoid unnecessary failovers for transient issues.
Correct Options:
A. In the event of a datacenter or Azure regional outage, the databases will fail over automatically.
This is the primary purpose of setting the failover policy to Automatic. Azure monitors the health of the primary Managed Instance. If a severe, persistent outage (like a datacenter or regional failure) is detected, Azure automatically initiates a failover of the entire instance (all databases in the failover group) to the secondary region after the grace period expires.
E. In the event of an outage, the minimum delay for the databases to fail over in the primary instance will be one hour.
The Automatic failover policy for Managed Instance failover groups has a fixed grace period of 1 hour. This means that even if an outage is detected, the automatic failover will not occur until at least one hour has passed. This prevents unnecessary failovers for short-lived transient issues.
Incorrect Options:
B. In the event of an outage, the databases in the primary instance will fail over immediately.
This is false because of the 1-hour grace period. Failover is not immediate; it is delayed by at least one hour to allow transient issues to resolve.
C. In the event of an outage, you can selectively fail over individual databases.
Failover groups for Managed Instance operate at the instance level. All databases within the instance fail over together as a single unit. You cannot selectively fail over individual databases.
D. In the event of an outage, you can set a different grace period to fail over each database.
The grace period is fixed at 1 hour for Managed Instance failover groups with Automatic policy and cannot be configured. Furthermore, failover is instance-wide, not per-database.
Reference:
Microsoft Docs - Auto-failover groups - Managed Instance - Failover policy
You are building a database backup solution for a SQL Server database hosted on an
Azure virtual machine.
In the event of an Azure regional outage, you need to be able to restore the database
backups. The solution must minimize costs.
Which type of storage accounts should you use for the backups?
A. locally-redundant storage (LRS)
B. read-access geo-redundant storage (RA-GRS)
C. zone-redundant storage (ZRS)
D. geo-redundant storage
>Explanation:
The requirement is to be able to restore database backups in the event of an Azure regional outage while minimizing costs. This means backups must be stored with geo-redundancy so a copy exists in a paired region if the primary region fails. Among geo-redundant options, Read-Access Geo-Redundant Storage (RA-GRS) provides the necessary regional resiliency at a lower cost than GRS because it offers read-only access to the secondary region.
Correct Option:
B. Read-access geo-redundant storage (RA-GRS)
RA-GRS replicates data to a secondary region and allows read access to the replicated data in that secondary region. This means if the primary region is down, you can still read and restore the backup files from the secondary region's endpoint. It is less expensive than Geo-Redundant Storage (GRS)? Actually, GRS does not allow read access to the secondary; you would need to wait for a Microsoft-initiated failover. RA-GRS provides immediate read access for disaster recovery at a slightly higher cost than GRS, but it's the most cost-effective choice for ensuring restorability without manual failover.
Incorrect Options:
A. Locally-redundant storage (LRS):
LRS only replicates within a single datacenter. It provides no protection against a regional outage, so backups would be unavailable.
C. Zone-redundant storage (ZRS):
ZRS replicates across availability zones within a single region. It protects against zone-level failures but not against a regional outage.
D. Geo-redundant storage (GRS):
GRS replicates to a secondary region, but the data in the secondary region is not readable unless Microsoft triggers a storage account failover (which is not customer-initiated for standard GRS). This means you cannot directly restore from the secondary region during an outage without a failover event, making it less suitable for immediate recovery.
Reference:
Microsoft Docs - Azure Storage redundancy
You have an Azure SQL database that contains a table named Customer. Customer has
the columns shown in the following table.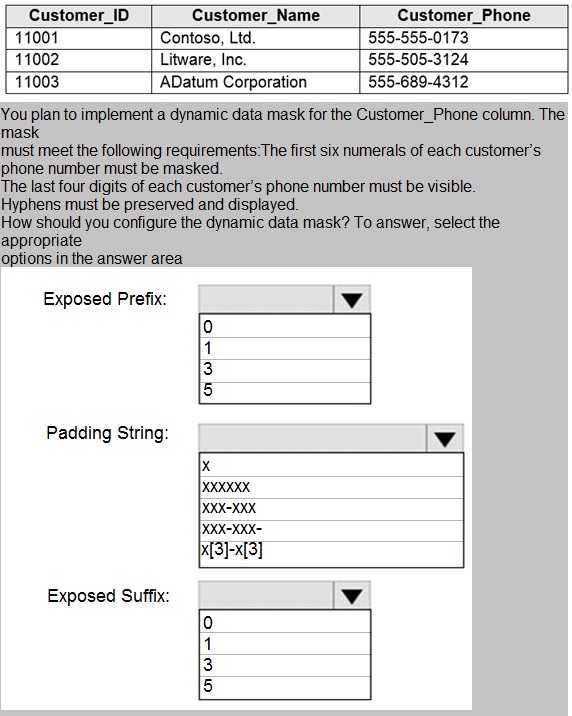
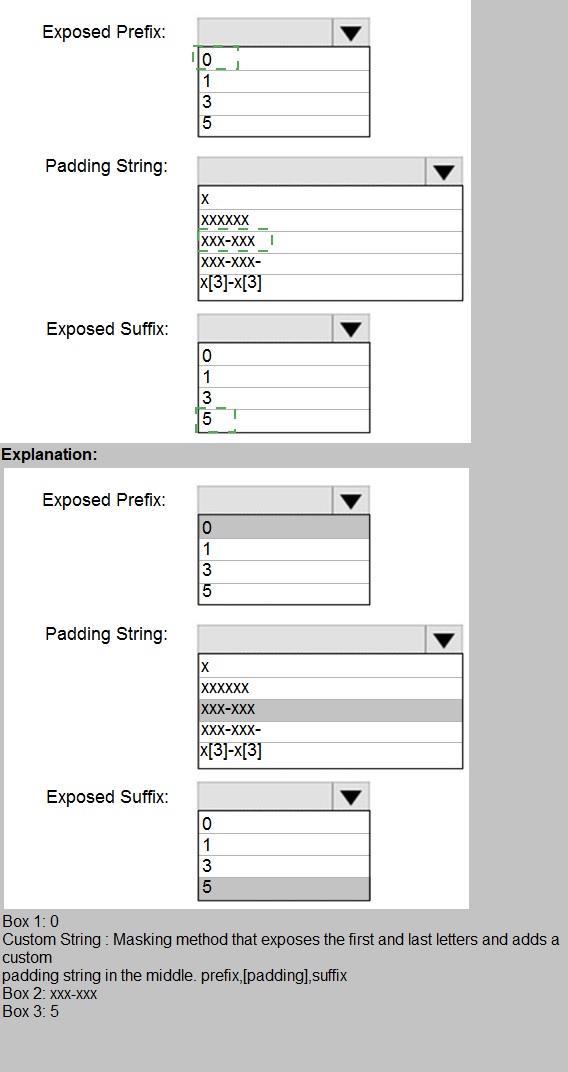
You have a Microsoft SQL Server database named DB1 that contains a table named
Table1.
The database role membership for a user named User1 is shown in the following exhibit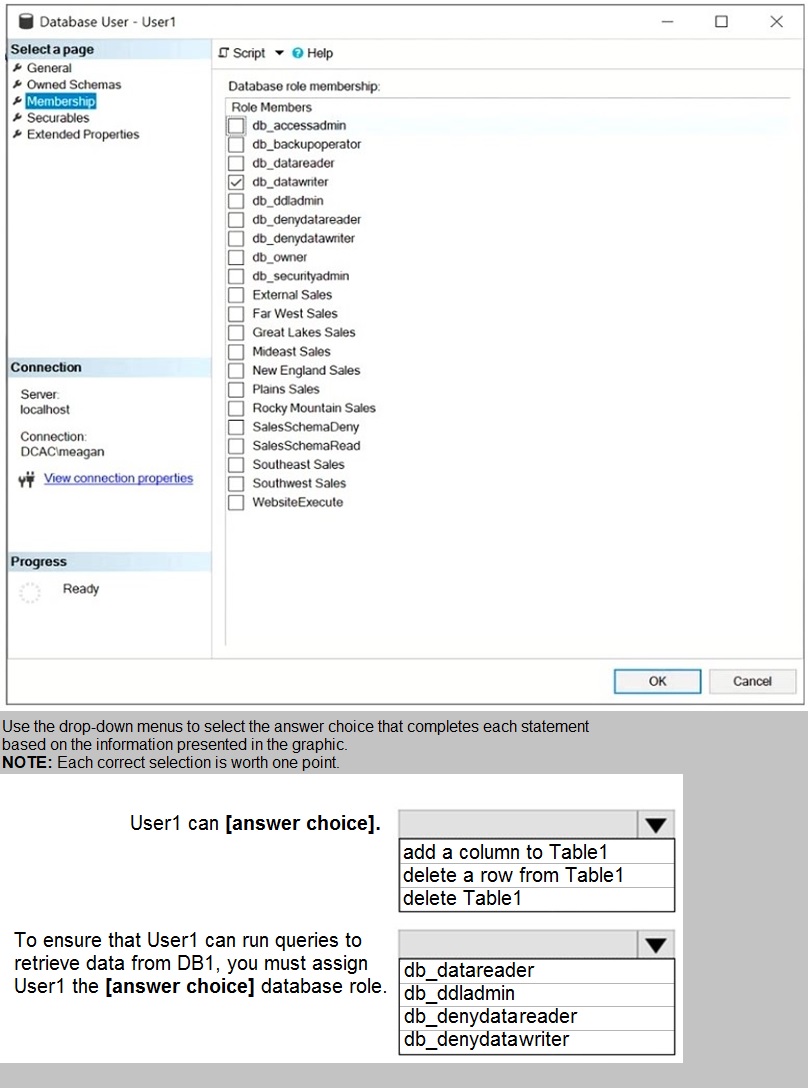
You have a resource group named App1Dev that contains an Azure SQL Database server
named DevServer1. DevServer1 contains an Azure SQL database named DB1. The
schema and permissions for DB1 are saved in a Microsoft SQL Server Data Tools (SSDT)
database project
You need to populate a new resource group named App1Test with the DB1 database and
an Azure SQL Server named TestServer1. The resources in App1Test must have the same
configurations as the resources in App1Dev.
Which four actions should you perform in sequence? To answer, move the appropriate
actions from the list of actions to the answer area and arrange them in the correct order.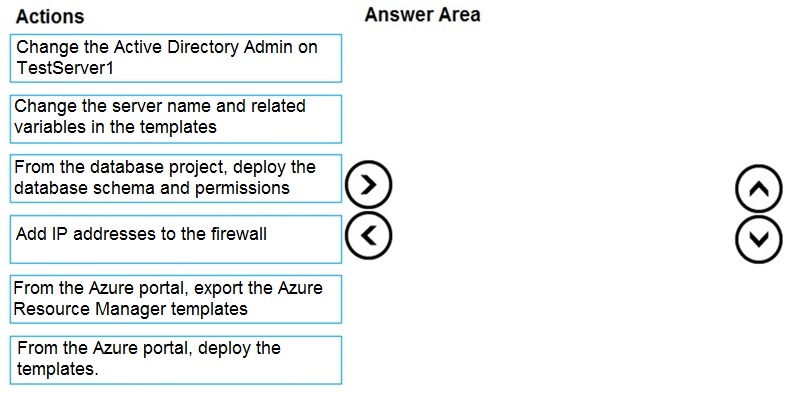
Note: This question is part of a series of questions that present the same scenario.
Each question in the series contains a unique solution that might meet the stated
goals. Some question sets might have more than one correct solution, while others
might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a
result, these questions will not appear in the review screen.
You have an Azure SQL database named Sales.
You need to implement disaster recovery for Sales to meet the following requirements:
During normal operations, provide at least two readable copies of Sales.
Ensure that Sales remains available if a datacenter fails.
Solution: You deploy an Azure SQL database that uses the General Purpose service tier
and failover groups.
Does this meet the goal?
A. Yes
B. No
Explanation:
Instead deploy an Azure SQL database that uses the Business Critical service tier and
Availability Zones.
Note: Premium and Business Critical service tiers leverage the Premium availability model,
which integrates compute resources (sqlservr.exe process) and storage (locally attached
SSD) on a single node. High availability is achieved by replicating both compute and
storage to additional nodes creating a three to four-node cluster.
By default, the cluster of nodes for the premium availability model is created in the same
datacenter. With the introduction of Azure Availability Zones, SQL Database can place
different replicas of the Business Critical database to different availability zones in the
same region. To eliminate a single point of failure, the control ring is also duplicated across
multiple zones as three gateway rings (GW).
Reference:
https://docs.microsoft.com/en-us/azure/azure-sql/database/high-availability-sla
You have an Azure SQL Database server named sqlsrv1 that hosts 10 Azure SQL
databases.
The databases perform slower than expected.
You need to identify whether the performance issue relates to the use of tempdb on
sqlsrv1.
What should you do?
A. Run Query Store-based queries
B. Review information provided by SQL Server Profiler-based traces
C. Review information provided by Query Performance Insight
D. Run dynamic management view-based queries
Explanation:
The diagnostics log outputs tempDB contention details. You can use the information as the
starting point for troubleshooting.
You can use the Intelligent Insights performance diagnostics log of Azure SQL Database to
troubleshoot performance issues.
Reference:
https://docs.microsoft.com/en-us/azure/azure-sql/database/intelligent-insights-troubleshootperformance#
tempdb-contention
https://docs.microsoft.com/en-us/azure/azure-sql/database/intelligent-insights-usediagnostics-
log
Note: This question is part of a series of questions that present the same scenario.
Each question in the series contains a unique solution that might meet the stated
goals. Some question sets might have more than one correct solution, while others
might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a
result, these questions will not appear in the review screen.
You have two Azure SQL Database servers named Server1 and Server2. Each server
contains an Azure SQL database named Database1.
You need to restore Database1 from Server1 to Server2. The solution must replace the
existing Database1 on Server2.
Solution: From the Azure portal, you delete Database1 from Server2, and then you create a
new database on Server2 by using the backup of Database1 from Server1.
Does this meet the goal?
A. Yes
B. No
Explanation:
Instead restore Database1 from Server1 to the Server2 by using the RESTORE Transact-
SQL command and the REPLACE option.
Note: REPLACE should be used rarely and only after careful consideration. Restore
normally prevents accidentally overwriting a database with a different database. If the
database specified in a RESTORE statement already exists on the current server and the
specified database family GUID differs from the database family GUID recorded in the
backup set, the database is not restored. This is an important safeguard.
Reference:
https://docs.microsoft.com/en-us/sql/t-sql/statements/restore-statements-transact-sql
| Page 3 out of 28 Pages |
| 123456789 |
| DP-300 Practice Test Home |
Real-World Scenario Mastery: Our DP-300 practice exam don't just test definitions. They present you with the same complex, scenario-based problems you'll encounter on the actual exam.
Strategic Weakness Identification: Each practice session reveals exactly where you stand. Discover which domains need more attention, before Administering Relational Databases on Microsoft Azure exam day arrives.
Confidence Through Familiarity: There's no substitute for knowing what to expect. When you've worked through our comprehensive DP-300 practice exam questions pool covering all topics, the real exam feels like just another practice session.
Copyright © All Rights Reserved