Topic 3, Mix Questions
You have an Azure Factory instance named DF1 that contains a pipeline named PL1.PL1
includes a tumbling window trigger.
You create five clones of PL1. You configure each clone pipeline to use a different data
source.
You need to ensure that the execution schedules of the clone pipeline match the execution
schedule of PL1.
What should you do?
A.
Add a new trigger to each cloned pipeline
B.
Associate each cloned pipeline to an existing trigger.
C.
Create a tumbling window trigger dependency for the trigger of PL1.
D.
Modify the Concurrency setting of each pipeline
Associate each cloned pipeline to an existing trigger.
What should you recommend using to secure sensitive customer contact information?
A.
data labels
B.
column-level security
C.
row-level security
D.
Transparent Data Encryption (TDE)
column-level security
Explanation:
Scenario: All cloud data must be encrypted at rest and in transit.
Always Encrypted is a feature designed to protect sensitive data stored in specific
database columns from access (for example, credit card numbers, national identification
numbers, or data on a need to know basis). This includes database administrators or other
privileged users who are authorized to access the database to perform management tasks,
but have no business need to access the particular data in the encrypted columns. The
data is always encrypted, which means the encrypted data is decrypted only for processing
by client applications with access to the encryption key.
References:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-security-overview
Note: This question is part of a series of questions that present the same scenario. Each
question in the series contains a unique solution that might meet the stated goals. Some
question sets might have more than one correct solution, while others might not have a
correct solution.
After you answer a question in this scenario, you will NOT be able to return to it. As a
result, these questions will not appear in the review screen.
You have an Azure Storage account that contains 100 GB of files. The files contain text
and numerical values. 75% of the rows contain description data that has an average length
of 1.1 MB.
You plan to copy the data from the storage account to an Azure SQL data warehouse.
You need to prepare the files to ensure that the data copies quickly.
Solution: You modify the files to ensure that each row is less than 1 MB.
Does this meet the goal?
A.
Yes
B.
No
Yes
Explanation:
When exporting data into an ORC File Format, you might get Java out-of-memory errors
when there are large text columns. To work around this limitation, export only a subset of
the columns.
References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/guidance-for-loading-data
You have an Apache Spark DataFrame named temperatures. A sample of the data is shown in the following table.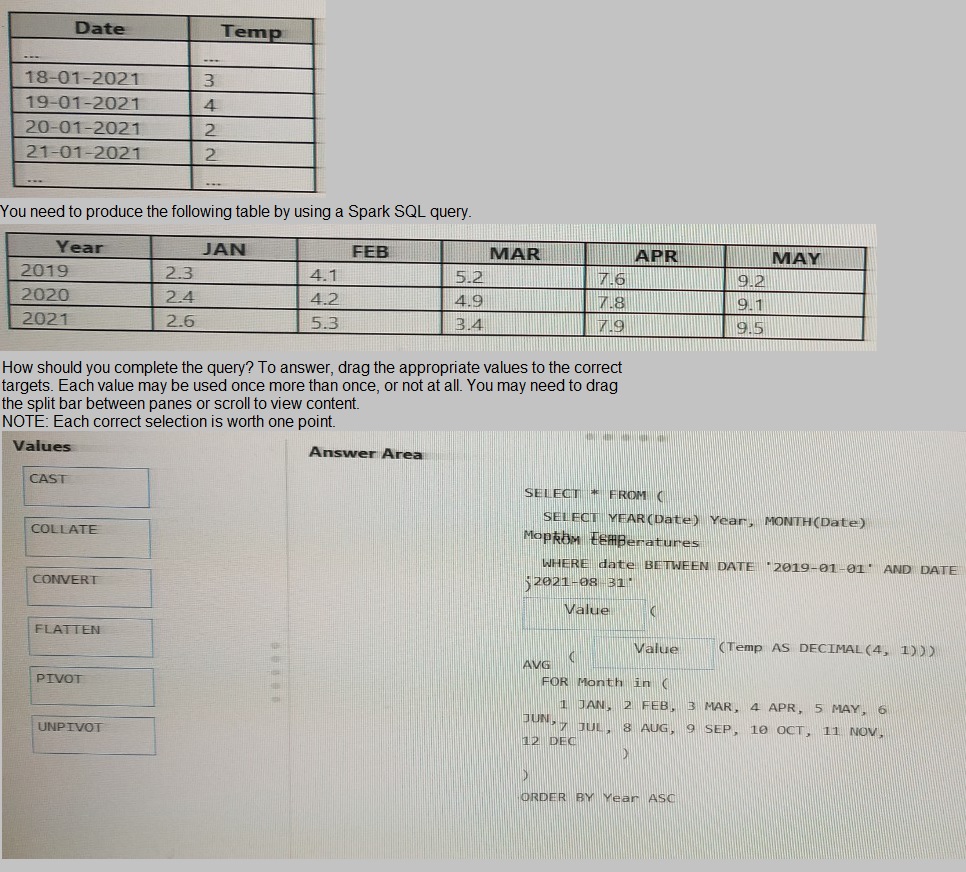
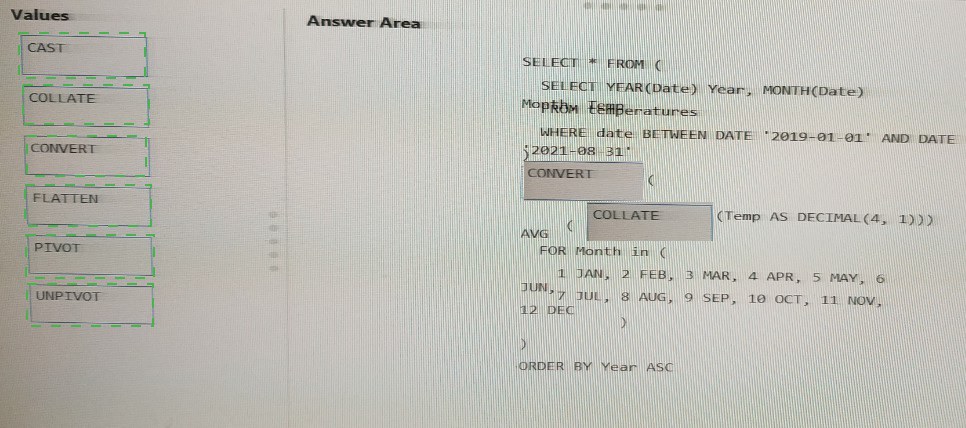
You are designing an Azure Databricks interactive cluster. The cluster will be used
infrequently and will be configured for auto-termination.
You need to ensure that the cluster configuration is retained indefinitely after the cluster is
terminated. The solution must minimize costs.
What should you do?
A.
Clone the cluster after it is terminated.
B.
Terminate the cluster manually when processing completes.
C.
Create an Azure runbook that starts the cluster every 90 days.
D.
Pin the cluster
Pin the cluster
Explanation:
To keep an interactive cluster configuration even after it has been terminated for more than
30 days, an
administrator can pin a cluster to the cluster list.
References:
https://docs.azuredatabricks.net/clusters/clusters-manage.html#automatic-termination
You have a Microsoft SQL Server database that uses a third normal form schema.
You plan to migrate the data in the database to a star schema in an A?\ire Synapse
Analytics dedicated SQI pool.
You need to design the dimension tables. The solution must optimize read operations.
What should you include in the solution? to answer, select the appropriate options in the
answer area.
NOTE: Each correct selection is worth one point

You have two Azure Data Factory instances named ADFdev and ADFprod. ADFdev
connects to an Azure DevOps Git repository.
You publish changes from the main branch of the Git repository to ADFdev.
You need to deploy the artifacts from ADFdev to ADFprod.
What should you do first?
A.
From ADFdev, modify the Git configuration.
B.
From ADFdev, create a linked service.
C.
From Azure DevOps, create a release pipeline.
D.
From Azure DevOps, update the main branch.
From Azure DevOps, create a release pipeline.
Explanation:
In Azure Data Factory, continuous integration and delivery (CI/CD) means moving Data
Factory pipelines from one environment (development, test, production) to another.
Note:
The following is a guide for setting up an Azure Pipelines release that automates the
deployment of a data factory to multiple environments.
In Azure DevOps, open the project that's configured with your data factory.
On the left side of the page, select Pipelines, and then select Releases.
Select New pipeline, or, if you have existing pipelines, select New and then New
release pipeline.
In the Stage name box, enter the name of your environment.
Select Add artifact, and then select the git repository configured with your
development data factory. Select the publish branch of the repository for the
Default branch. By default, this publish branch is adf_publish.
Select the Empty job template.
Reference:
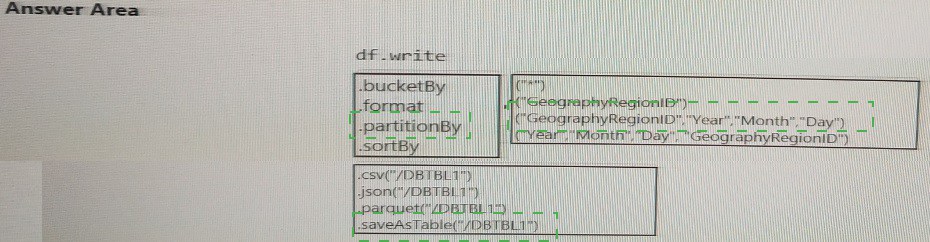
You develop a dataset named DBTBL1 by using Azure Databricks.
DBTBL1 contains the following columns:
• SensorTypelD
• GeographyRegionID
• Year
• Month
• Day
• Hour
• Minute
• Temperature
• WindSpeed
• Other
You need to store the data to support daily incremental load pipelines that vary for each
GeographyRegionID. The solution must minimize storage costs.
How should you complete the code? To answer, select the appropriate options in the
answer area.
NOTE: Each correct selection is worth one poin
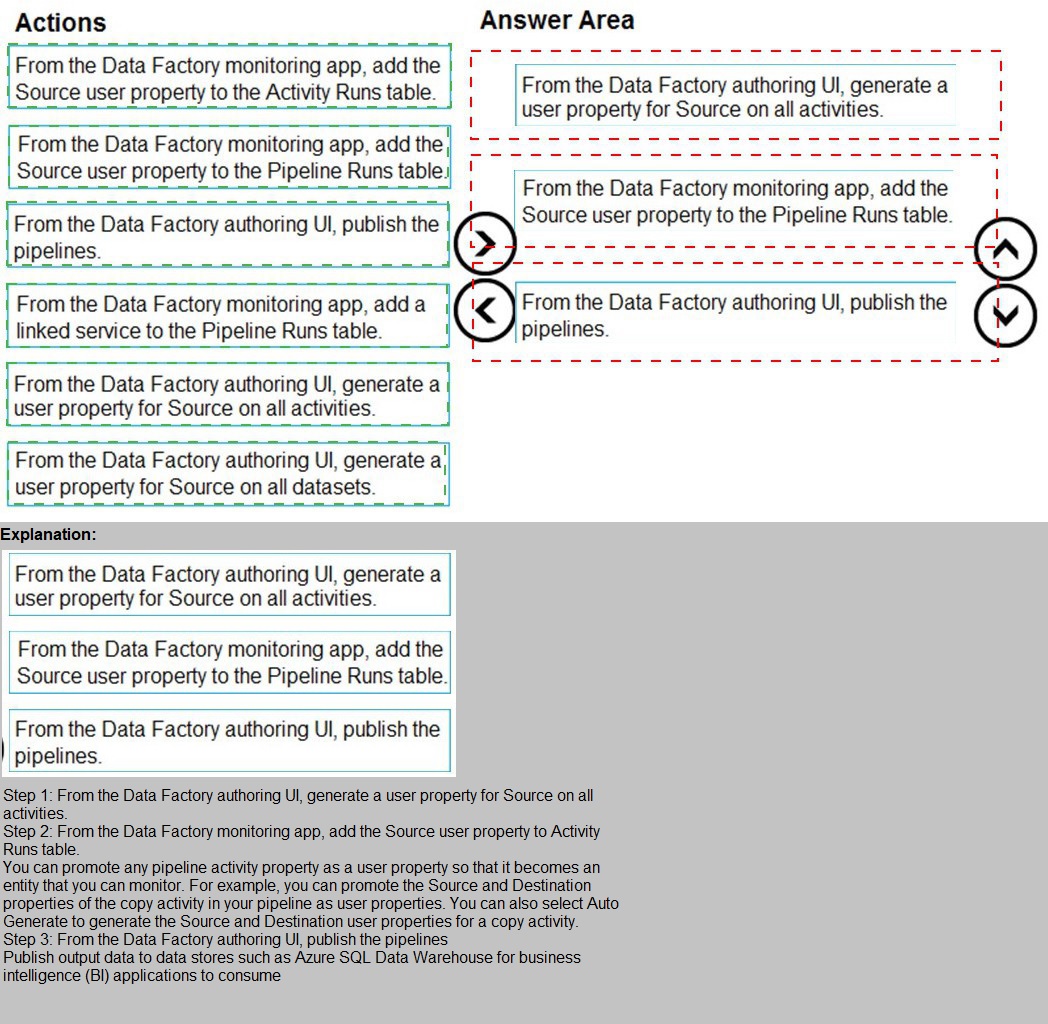
You plan to monitor an Azure data factory by using the Monitor & Manage app.
You need to identify the status and duration of activities that reference a table in a source
database.
Which three actions should you perform in sequence? To answer, move the actions from
the list of actions to the answer are and arrange them in the correct order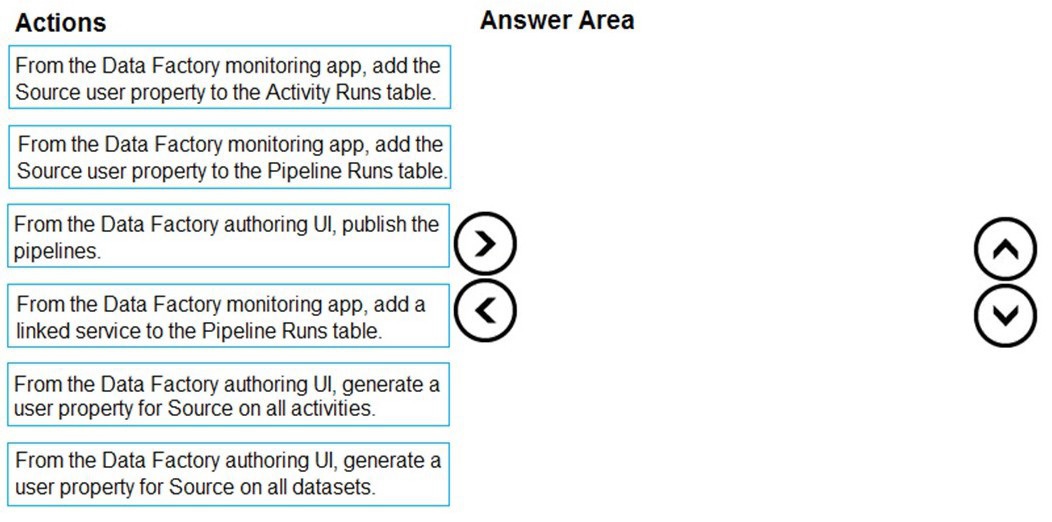
You need to create an Azure Data Factory pipeline to process data for the following three
departments at your company: Ecommerce, retail, and wholesale. The solution must
ensure that data can also be processed for the entire company.
How should you complete the Data Factory data flow script? To answer, drag the
appropriate values to the correct targets. Each value may be used once, more than once,
or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.

You have an Azure Data Lake Storage Gen2 container.
Data is ingested into the container, and then transformed by a data integration application.
The data is NOT modified after that. Users can read files in the container but cannot modify
the files.
You need to design a data archiving solution that meets the following requirements:
New data is accessed frequently and must be available as quickly as possible.
Data that is older than five years is accessed infrequently but must be available
within one second when requested.
Data that is older than seven years is NOT accessed. After seven years, the data
must be persisted at the lowest cost possible.
Costs must be minimized while maintaining the required availability.
How should you manage the data? To answer, select the appropriate options in the answer
area.
NOTE: Each correct selection is worth one point

You are designing a slowly changing dimension (SCD) for supplier data in an Azure
Synapse Analytics dedicated SQL pool.
You plan to keep a record of changes to the available fields.
The supplier data contains the following columns.
Which three additional columns should you add to the data to create a Type 2 SCD? Each
correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A.
surrogate primary key
B.
foreign key
C.
effective start date
D.
effective end date
E.
last modified date
F.
business key
foreign key
effective start date
business key
| Page 7 out of 18 Pages |
| Previous |