Topic 3, Mix Questions
You are designing a solution that will copy Parquet files stored in an Azure Blob storage
account to an Azure Data Lake Storage Gen2 account.
The data will be loaded daily to the data lake and will use a folder structure of
{Year}/{Month}/{Day}/.
You need to design a daily Azure Data Factory data load to minimize the data transfer
between the two
accounts.
Which two configurations should you include in the design? Each correct answer presents
part of the solution.
NOTE: Each correct selection is worth one point.
A.
Delete the files in the destination before loading new data.
B.
Filter by the last modified date of the source files.
C.
Delete the source files after they are copied.
D.
Specify a file naming pattern for the destination.
Filter by the last modified date of the source files.
Delete the source files after they are copied.
You have several Azure Data Factory pipelines that contain a mix of the following types of
activities.
* Wrangling data flow
* Notebook
* Copy
* jar
Which two Azure services should you use to debug the activities? Each correct answer
presents part of the solution NOTE: Each correct selection is worth one point.
A.
Azure HDInsight
B.
Azure Databricks
C.
Azure Machine Learning
D.
Azure Data Factory
E.
Azure Synapse Analytics
Azure Machine Learning
Azure Synapse Analytics
You are designing a partition strategy for a fact table in an Azure Synapse Analytics
dedicated SQL pool. The table has the following specifications:
• Contain sales data for 20,000 products
• Use hash distribution on a column named ProduclID,
• Contain 2.4 billion records for the years 20l9 and 2020.
Which number of partition ranges provides optimal compression and performance of the
clustered columnstore index?
A.
40
B.
240
C.
400
D.
2,400
240
You have a SQL pool in Azure Synapse.
A user reports that queries against the pool take longer than expected to complete.
You need to add monitoring to the underlying storage to help diagnose the issue.
Which two metrics should you monitor? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A.
Cache used percentage
B.
DWU Limit
C.
Snapshot Storage Size
D.
Active queries
E.
Cache hit percentage
Cache used percentage
Cache hit percentage
You have the following Azure Stream Analytics query.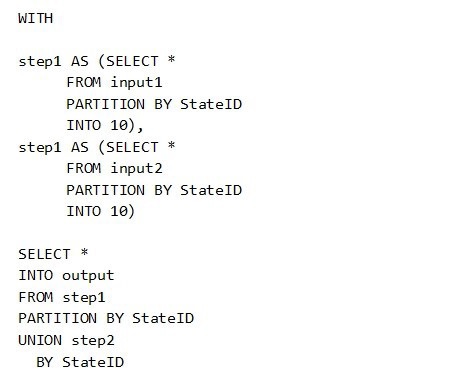

You are implementing Azure Stream Analytics windowing functions.
Which windowing function should you use for each requirement? To answer, select the
appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

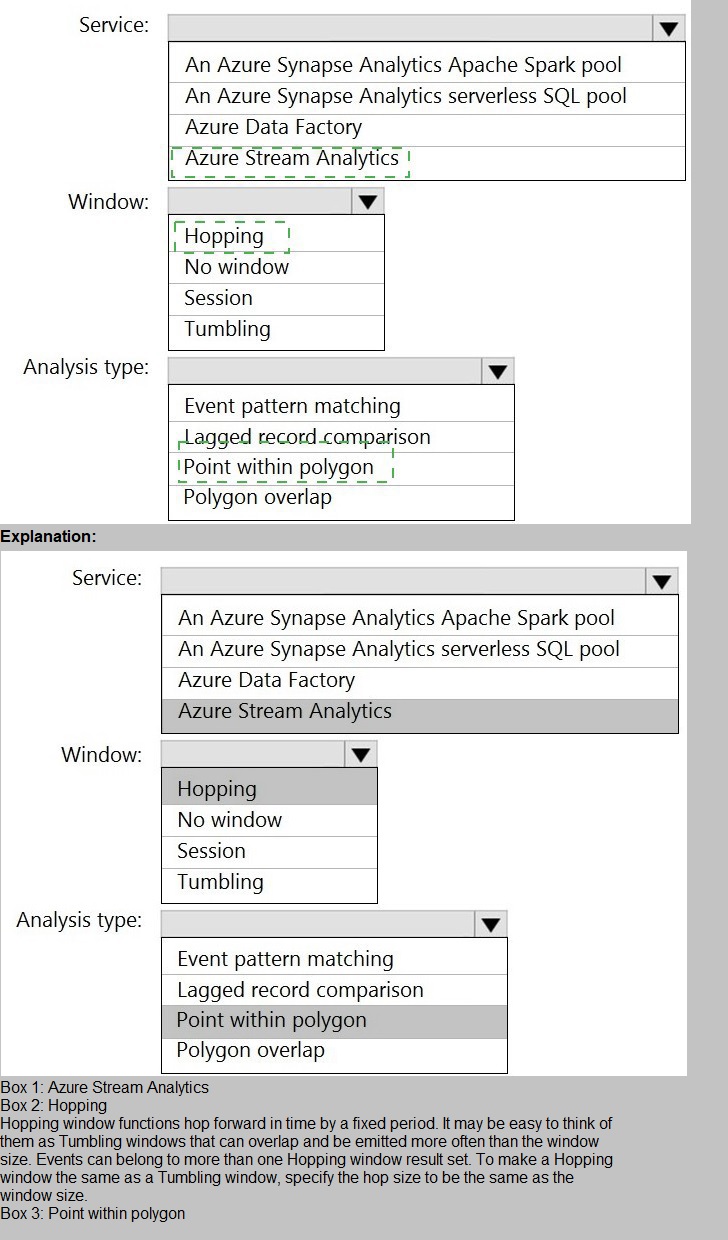
You are designing a monitoring solution for a fleet of 500 vehicles. Each vehicle has a GPS
tracking device that sends data to an Azure event hub once per minute.
You have a CSV file in an Azure Data Lake Storage Gen2 container. The file maintains the
expected geographical area in which each vehicle should be.
You need to ensure that when a GPS position is outside the expected area, a message is
added to another event hub for processing within 30 seconds. The solution must minimize
cost.
What should you include in the solution? To answer, select the appropriate options in the
answer area.
NOTE: Each correct selection is worth one point.
Question No : 69 HOTSPOT - (Topic 3)
Microsoft DP-203 : Practice Test
77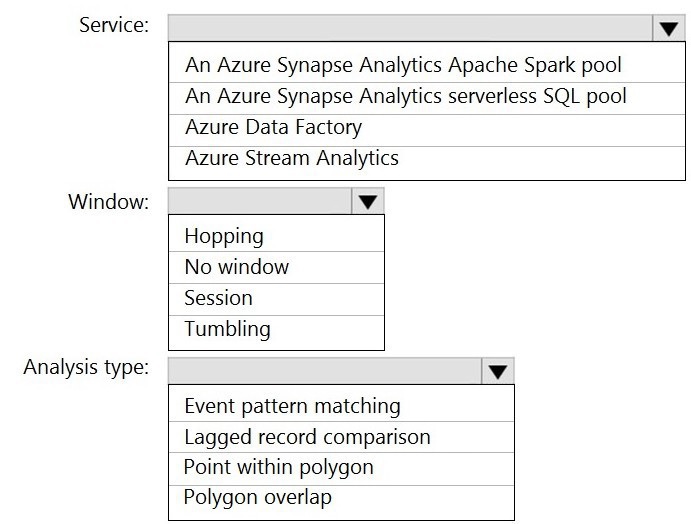
You are designing a real-time dashboard solution that will visualize streaming data from remote sensors that connect to the internet. The streaming data must be aggregated to 

You have an Azure SQL database named Database1 and two Azure event hubs named HubA and HubB. The data consumed from each source is shown in the following table 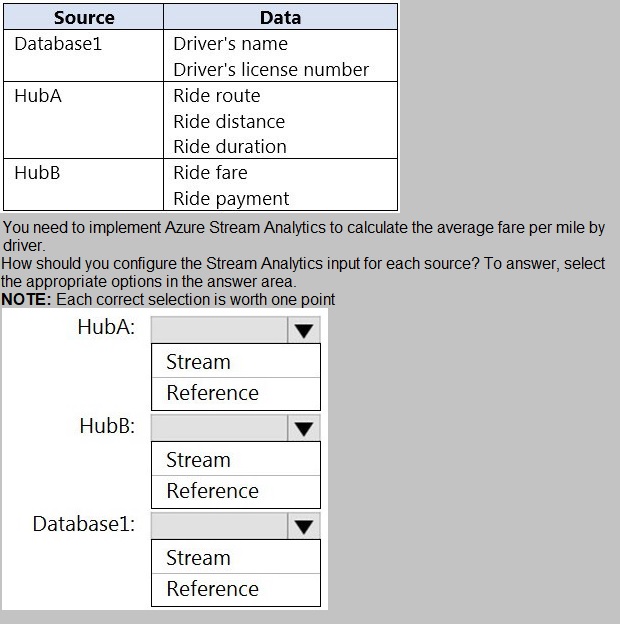
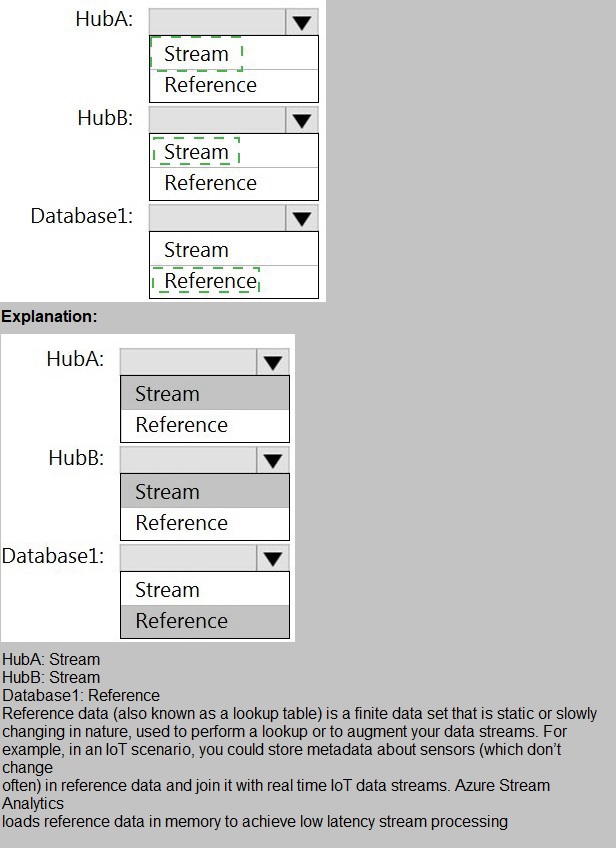
You use Azure Data Factory to prepare data to be queried by Azure Synapse Analytics
serverless SQL pools.
Files are initially ingested into an Azure Data Lake Storage Gen2 account as 10 small
JSON files. Each file contains the same data attributes and data from a subsidiary of your
company.
You need to move the files to a different folder and transform the data to meet the following
requirements:
Provide the fastest possible query times.
Automatically infer the schema from the underlying files.
How should you configure the Data Factory copy activity? To answer, select the
appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
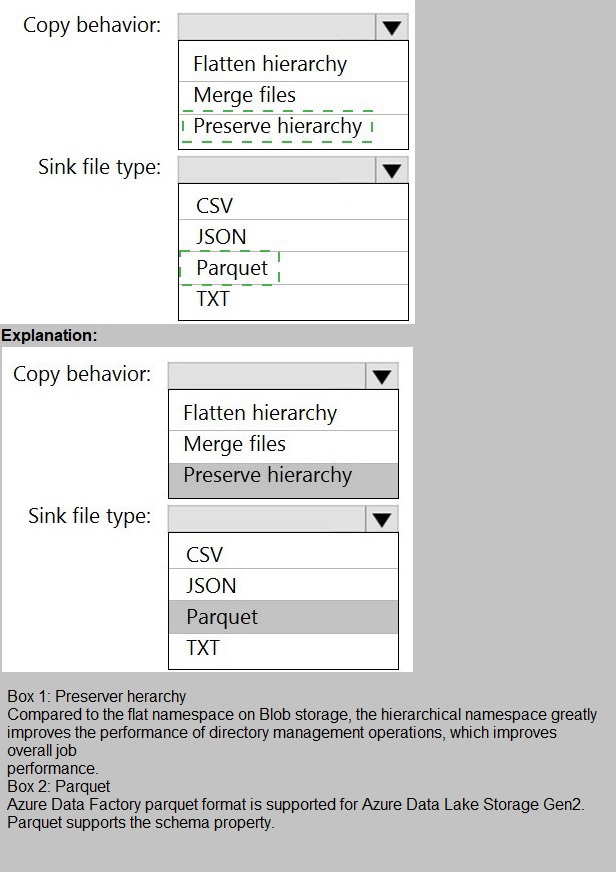
You have an Azure Synapse Analytics job that uses Scala.
You need to view the status of the job.
What should you do?
A.
From Azure Monitor, run a Kusto query against the AzureDiagnostics table.
B.
From Azure Monitor, run a Kusto query against the SparkLogying1 Event.CL table.
C.
From Synapse Studio, select the workspace. From Monitor, select Apache Sparks applications.
D.
From Synapse Studio, select the workspace. From Monitor, select SQL requests.
From Synapse Studio, select the workspace. From Monitor, select Apache Sparks applications.
You have an Azure Databricks workspace named workspace1 in the Standard pricing tier.
You need to configure workspace1 to support autoscaling all-purpose clusters. The solution
must meet the following requirements:
Automatically scale down workers when the cluster is underutilized for three
minutes.
Minimize the time it takes to scale to the maximum number of workers.
Minimize costs.
What should you do first?
A.
Enable container services for workspace1.
B.
Upgrade workspace1 to the Premium pricing tier.
C.
Set Cluster Mode to High Concurrency.
D.
Create a cluster policy in workspace1.
Upgrade workspace1 to the Premium pricing tier.
Explanation:
For clusters running Databricks Runtime 6.4 and above, optimized autoscaling is used by
all-purpose clusters
in the Premium plan
Optimized autoscaling:
Scales up from min to max in 2 steps.
Can scale down even if the cluster is not idle by looking at shuffle file state.
Scales down based on a percentage of current nodes.
On job clusters, scales down if the cluster is underutilized over the last 40 seconds.
On all-purpose clusters, scales down if the cluster is underutilized over the last 150
seconds.
The spark.databricks.aggressiveWindowDownS Spark configuration property specifies in
seconds how often a
cluster makes down-scaling decisions. Increasing the value causes a cluster to scale down
more slowly. The
maximum value is 600.
Note: Standard autoscaling
Starts with adding 8 nodes. Thereafter, scales up exponentially, but can take many steps to
reach the max. You
can customize the first step by setting the
spark.databricks.autoscaling.standardFirstStepUp Spark
configuration property.
Scales down only when the cluster is completely idle and it has been underutilized for the
last 10 minutes.
Scales down exponentially, starting with 1 node.
Reference:
https://docs.databricks.com/clusters/configure.html
| Page 6 out of 18 Pages |
| Previous |