Topic 3, Mix Questions
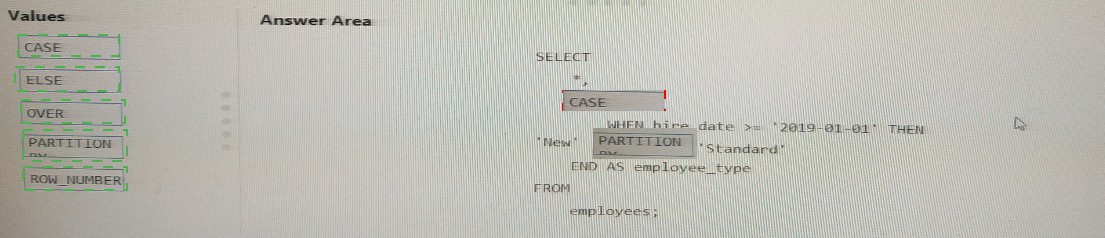
You have the following table named Employees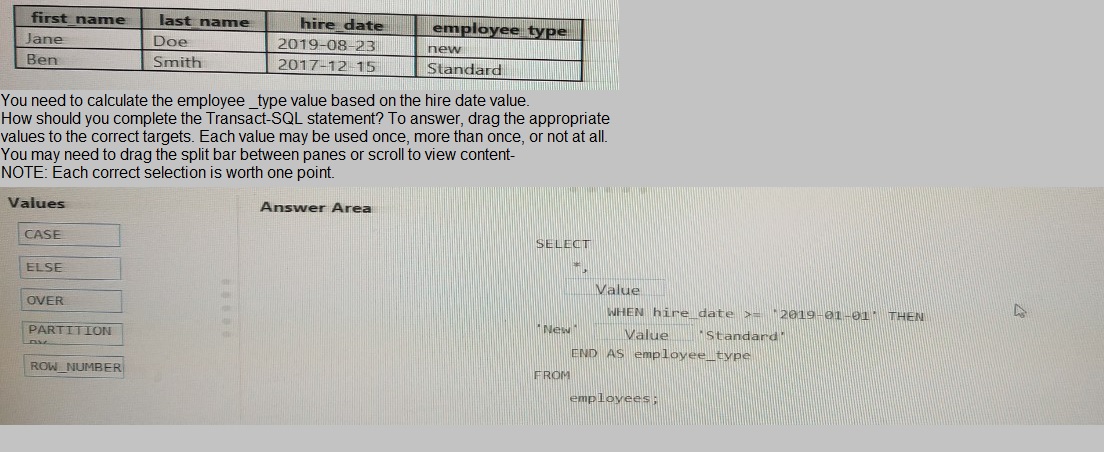
You have an enterprise-wide Azure Data Lake Storage Gen2 account. The data lake is
accessible only through an Azure virtual network named VNET1.
You are building a SQL pool in Azure Synapse that will use data from the data lake.
Your company has a sales team. All the members of the sales team are in an Azure Active
Directory group named Sales. POSIX controls are used to assign the Sales group access
to the files in the data lake.
You plan to load data to the SQL pool every hour.
You need to ensure that the SQL pool can load the sales data from the data lake.
Which three actions should you perform? Each correct answer presents part of the
solution.
NOTE: Each area selection is worth one point.
A.
Add the managed identity to the Sales group.
B.
Use the managed identity as the credentials for the data load process.
C.
Create a shared access signature (SAS).
D.
Add your Azure Active Directory (Azure AD) account to the Sales group.
E.
Use the snared access signature (SAS) as the credentials for the data load process.
F.
Create a managed identity.
Add the managed identity to the Sales group.
Add your Azure Active Directory (Azure AD) account to the Sales group.
Create a managed identity.
You have an enterprise data warehouse in Azure Synapse Analytics named DW1 on a server named Server1. You need to verify whether the size of the transaction log file for each distribution of DW1 is smaller than 160 GB.
What should you do?
A.
On the master database, execute a query against the
sys.dm_pdw_nodes_os_performance_counters dynamic management view.
B.
From Azure Monitor in the Azure portal, execute a query against the logs of DW1.
C.
On DW1, execute a query against the sys.database_files dynamic management view.
D.
Execute a query against the logs of DW1 by using the
Get-AzOperationalInsightSearchResult PowerShell cmdlet
On the master database, execute a query against the
sys.dm_pdw_nodes_os_performance_counters dynamic management view.
Explanation:
The following query returns the transaction log size on each distribution. If one of the log
files is reaching 160 GB, you should consider scaling up your instance or limiting your
transaction size.
- Transaction log size
SELECT
instance_name as distribution_db,
cntr_value*1.0/1048576 as log_file_size_used_GB,
pdw_node_id
FROM sys.dm_pdw_nodes_os_performance_counters
WHERE
instance_name like 'Distribution_%'
AND counter_name = 'Log File(s) Used Size (KB)'
References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-managemonitor
A company purchases IoT devices to monitor manufacturing machinery. The company uses an IoT appliance to communicate with the IoT devices.
The company must be able to monitor the devices in real-time.
You need to design the solution.
What should you recommend?
A.
Azure Stream Analytics cloud job using Azure PowerShell
B.
Azure Analysis Services using Azure Portal
C.
Azure Data Factory instance using Azure Portal
D.
Azure Analysis Services using Azure PowerShell
Azure Stream Analytics cloud job using Azure PowerShell
Explanation:
Stream Analytics is a cost-effective event processing engine that helps uncover real-time
insights from devices, sensors, infrastructure, applications and data quickly and easily.
Monitor and manage Stream Analytics resources with Azure PowerShell cmdlets and
powershell scripting that execute basic Stream Analytics tasks.
Reference:
https://cloudblogs.microsoft.com/sqlserver/2014/10/29/microsoft-adds-iot-streaminganalytics-
data-production-and-workflow-services-to-azure/
You use Azure Data Lake Storage Gen2.
You need to ensure that workloads can use filter predicates and column projections to filter
data at the time the data is read from disk.
Which two actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A.
Reregister the Microsoft Data Lake Store resource provider.
B.
Reregister the Azure Storage resource provider.
C.
Create a storage policy that is scoped to a container.
D.
Register the query acceleration feature.
E.
Create a storage policy that is scoped to a container prefix filter.
Reregister the Azure Storage resource provider.
Register the query acceleration feature.
Note: This question is part of a series of questions that present the same scenario.
Each question in the series contains a unique solution that might meet the stated
goals. Some question sets might have more than one correct solution, while others
might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a
result, these questions will not appear in the review screen.
You plan to create an Azure Databricks workspace that has a tiered structure. The
workspace will contain the following three workloads:
A workload for data engineers who will use Python and SQL.
A workload for jobs that will run notebooks that use Python, Scala, and SOL.
A workload that data scientists will use to perform ad hoc analysis in Scala and R.
The enterprise architecture team at your company identifies the following standards for
Databricks environments:
The data engineers must share a cluster.
The job cluster will be managed by using a request process whereby data
scientists and data engineers provide packaged notebooks for deployment to the
cluster.
All the data scientists must be assigned their own cluster that terminates
automatically after 120 minutes of inactivity. Currently, there are three data
scientists.
You need to create the Databricks clusters for the workloads.
Solution: You create a Standard cluster for each data scientist, a High Concurrency cluster
for the data engineers, and a High Concurrency cluster for the jobs.
Does this meet the goal?
A.
Yes
B.
No
Yes
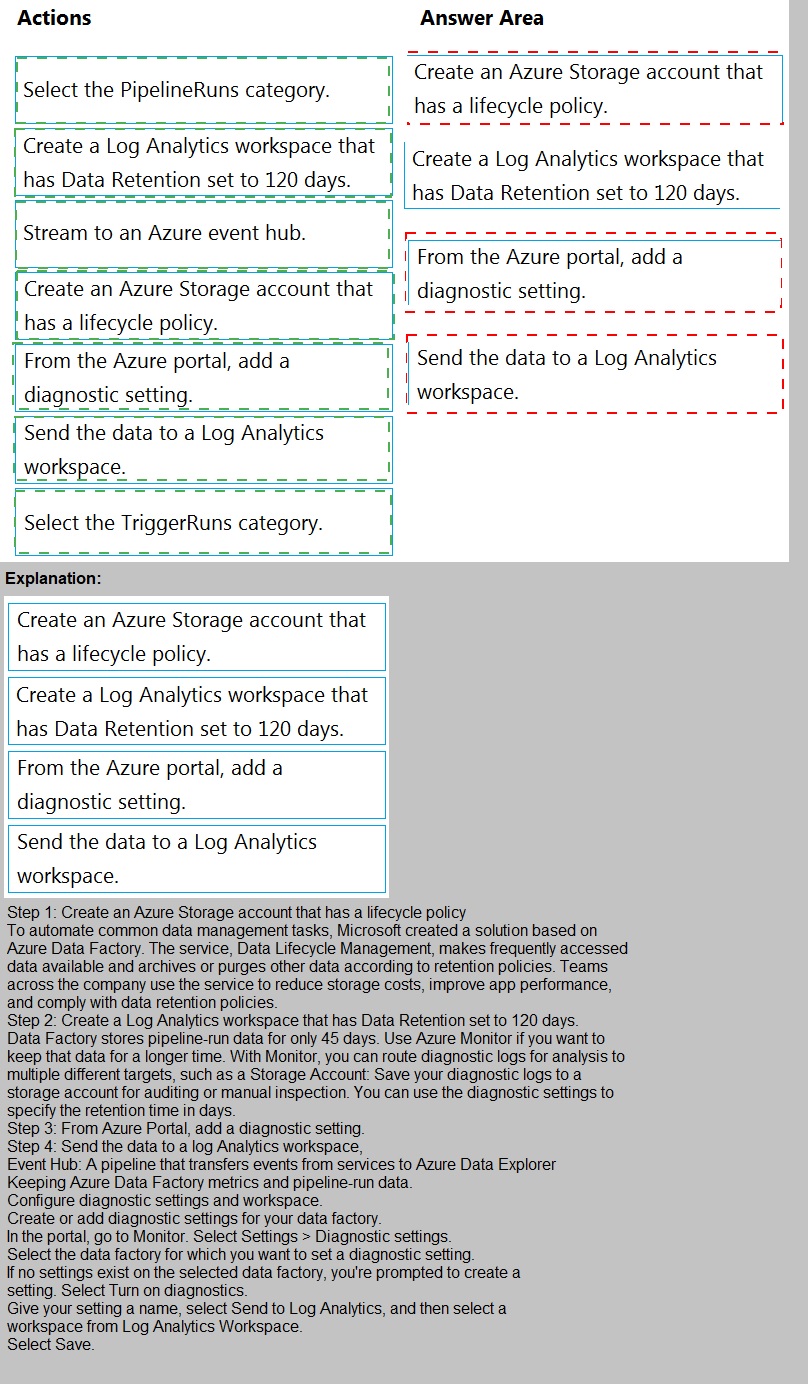
You have an Azure data factory.
You need to ensure that pipeline-run data is retained for 120 days. The solution must
ensure that you can query the data by using the Kusto query language.
Which four actions should you perform in sequence? To answer, move the appropriate
actions from the list of actions to the answer area and arrange them in the correct order.
NOTE: More than one order of answer choices is correct. You will receive credit for any of
the correct orders you select.
You have an Azure Data Lake Storage Gen2 container that contains 100 TB of data.
You need to ensure that the data in the container is available for read workloads in a
secondary region if an outage occurs in the primary region. The solution must minimize
costs.
Which type of data redundancy should you use?
A.
zone-redundant storage (ZRS)
B.
read-access geo-redundant storage (RA-GRS)
C.
locally-redundant storage (LRS)
D.
geo-redundant storage (GRS)
locally-redundant storage (LRS)
Note: This question is part of a series of questions that present the same scenario. Each
question in the series contains a unique solution that might meet the stated goals. Some
question sets might have more than one correct solution, while others might not have a
correct solution.
After you answer a question in this scenario, you will NOT be able to return to it. As a
result, these questions will not appear in the review screen.
You have an Azure Storage account that contains 100 GB of files. The files contain text
and numerical values. 75% of the rows contain description data that has an average length
of 1.1 MB.
You plan to copy the data from the storage account to an enterprise data warehouse in
Azure Synapse Analytics.
You need to prepare the files to ensure that the data copies quickly.
Solution: You convert the files to compressed delimited text files.
Does this meet the goal?
A.
Yes
B.
No
Yes
All file formats have different performance characteristics. For the fastest load, use
compressed delimited text files.
Reference:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/guidance-for-loading-data
You are developing a solution that will stream to Azure Stream Analytics. The solution will
have both streaming data and reference data.
Which input type should you use for the reference data?
A.
Azure Cosmos DB
B.
Azure Blob storage
C.
Azure IoT Hub
D.
Azure Event Hubs
Azure Blob storage
Explanation:
Stream Analytics supports Azure Blob storage and Azure SQL Database as the storage
layer for Reference Data.
Reference:
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-use-referencedata
You have a table in an Azure Synapse Analytics dedicated SQL pool. The table was created by using the following Transact-SQL statement.
You need to alter the table to meet the following requirements:
Ensure that users can identify the current manager of employees.
Support creating an employee reporting hierarchy for your entire company.
Provide fast lookup of the managers’ attributes such as name and job title.
Which column should you add to the table?
A.
[ManagerEmployeeID] [int] NULL
B.
[ManagerEmployeeID] [smallint] NULL
C.
[ManagerEmployeeKey] [int] NULL
D.
[ManagerName] [varchar](200) NULL
[ManagerEmployeeID] [int] NULL
Explanation:
Use the same definition as the EmployeeID column.
Reference:
https://docs.microsoft.com/en-us/analysis-services/tabular-models/hierarchies-ssas-tabular
You are designing a fact table named FactPurchase in an Azure Synapse Analytics dedicated SQL pool. The table contains purchases from suppliers for a retail store. FactPurchase will contain the following columns.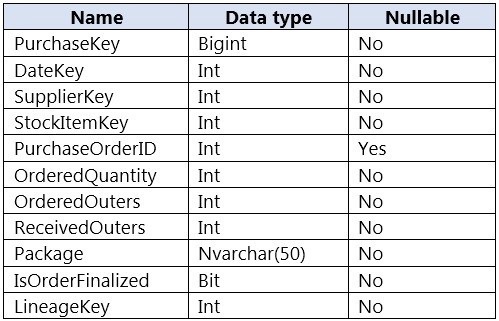
FactPurchase will have 1 million rows of data added daily and will contain three years of
data.
Transact-SQL queries similar to the following query will be executed daily.
SELECT
SupplierKey, StockItemKey, COUNT(*)
FROM FactPurchase
WHERE DateKey >= 20210101
AND DateKey <= 20210131
GROUP By SupplierKey, StockItemKey
Which table distribution will minimize query times?
A.
round-robin
B.
replicated
C.
hash-distributed on DateKey
D.
hash-distributed on PurchaseKey
hash-distributed on PurchaseKey
Hash-distributed tables improve query performance on large fact tables, and are the focus
of this article. Round-robin tables are useful for improving loading speed.
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-datawarehouse-
tables-distribute
| Page 4 out of 18 Pages |
| Previous |